Git操作学习——从一个可视化的git练习网站说起
前言
自以为自己已经学会了使用git,但是当我被分配了大量的bug需要修复并且大量使用git时才知道自己的git的掌握程度有多菜,因此回家开始补习git的操作了。
最好的练习方式自然是能够可视化的进行练习,因此我找到了一个进行可视化练习git操作的网站Learngitbranching来学习git相关的操作,本文为学习的记录,以便后续查询使用。
Git 本地操作
git commit——提交更改
git commit 主要是用于记录下各种修改的历史记录,git commit 的提交记录类似文件快照,但做的非常轻量化。
Git 希望提交记录尽可能地轻量,因此在你每次进行提交时,它并不会盲目地复制整个目录。条件允许的情况下,它会将当前版本与仓库中的上一个版本进行对比,并把所有的差异打包到一起作为一个提交记录。
进行git commit的时候,他会将你add过的文件进行提交,每次提交会检查当前目录下所有跟踪的文件是否发生了变化,如果有则会提醒你进行add,在所有跟踪了的文件都add了以后,Git会保存add了的文件与上次提交间的差异,并要求你输入一定的commit message。
git branch——新建分支
Git 的分支也非常轻量。它们只是简单地指向某个提交纪录 —— 仅此而已。所以许多 Git 爱好者传颂:
1 | 早建分支!多用分支! |
这是因为即使创建再多的分支也不会造成储存或内存上的开销,因为分支只是相当于新建了个指向当前提交的指针而已,并不会复制任何文件,并且按逻辑分解工作到不同的分支要比维护那些特别臃肿的分支简单多了。
在将分支和提交记录结合起来后,我们会看到两者如何协作。现在只要记住使用分支其实就相当于在说:“我想基于这个提交以及它所有的 parent 提交进行新的工作。”
1 | git branch NewBranch |
这个语句仅仅相当于新建一个名为NewBranch的分支,指向目前最新的一个提交。
分支相关的操作如下
1 | // 创建分支 |
git merge——合并分支
使用 git merge在 Git 中合并两个分支时会产生一个特殊的提交记录,它有两个 parent 节点。翻译成自然语言相当于:“我要把这两个 parent 节点本身及它们所有的祖先都包含进来。
当目前工作区中没有未提交的更改并且不产生冲突时,git merge bugFix操作会将下图的C2、C3提交合并到一起并产生一个新提交C4
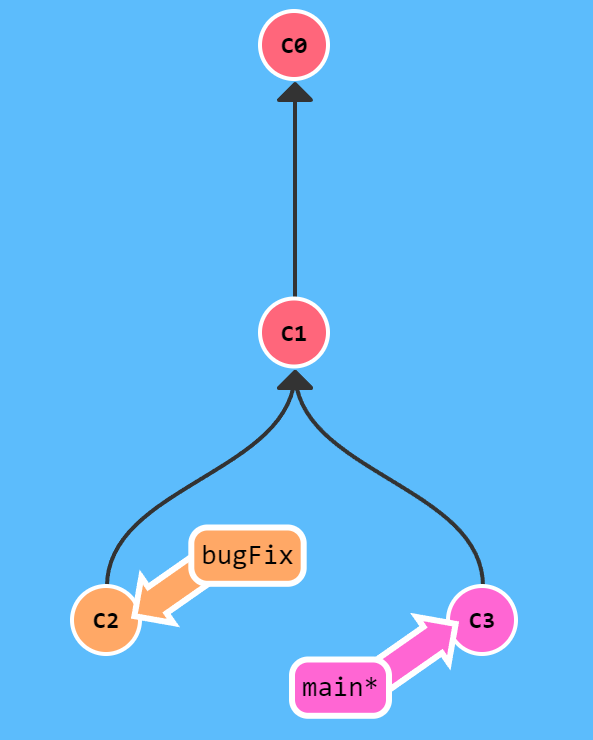
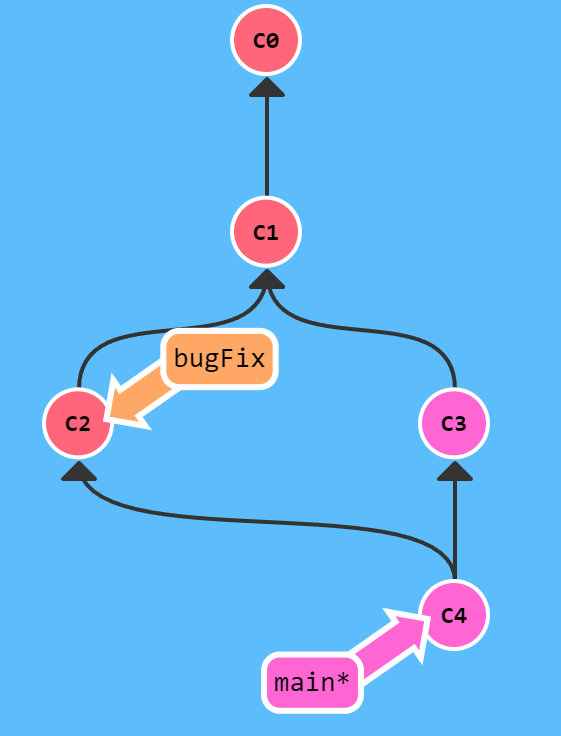
1 | // 当前分支与目标分支合并 |
由于git merge会在本地产生一个merge的提交,而一般远程不会允许普通开发者进行merge操作,故我们在本地进行开发时一般不适用merge操作,更常用的是rabase操作
git rebase——分支合并方法之二
第二种合并分支的方法是 git rebase。Rebase 实际上就是取出一系列的提交记录,“复制”它们,然后在另外一个地方逐个的放下去。
Rebase 的优势就是可以创造更线性的提交历史,这听上去有些难以理解。如果只允许使用 Rebase 的话,代码库的提交历史将会变得异常清晰。
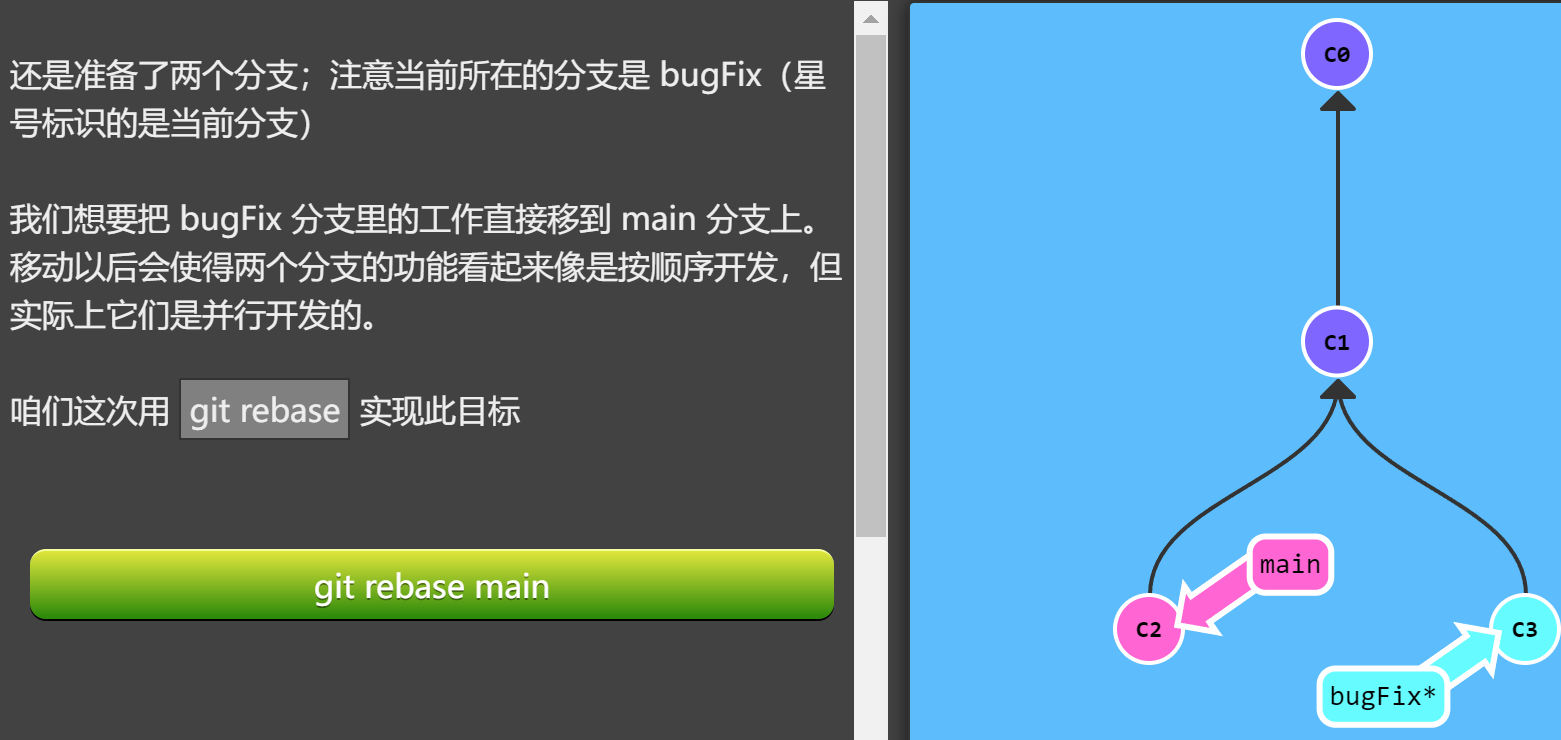
执行git rebase main后得到下图所示提交情况
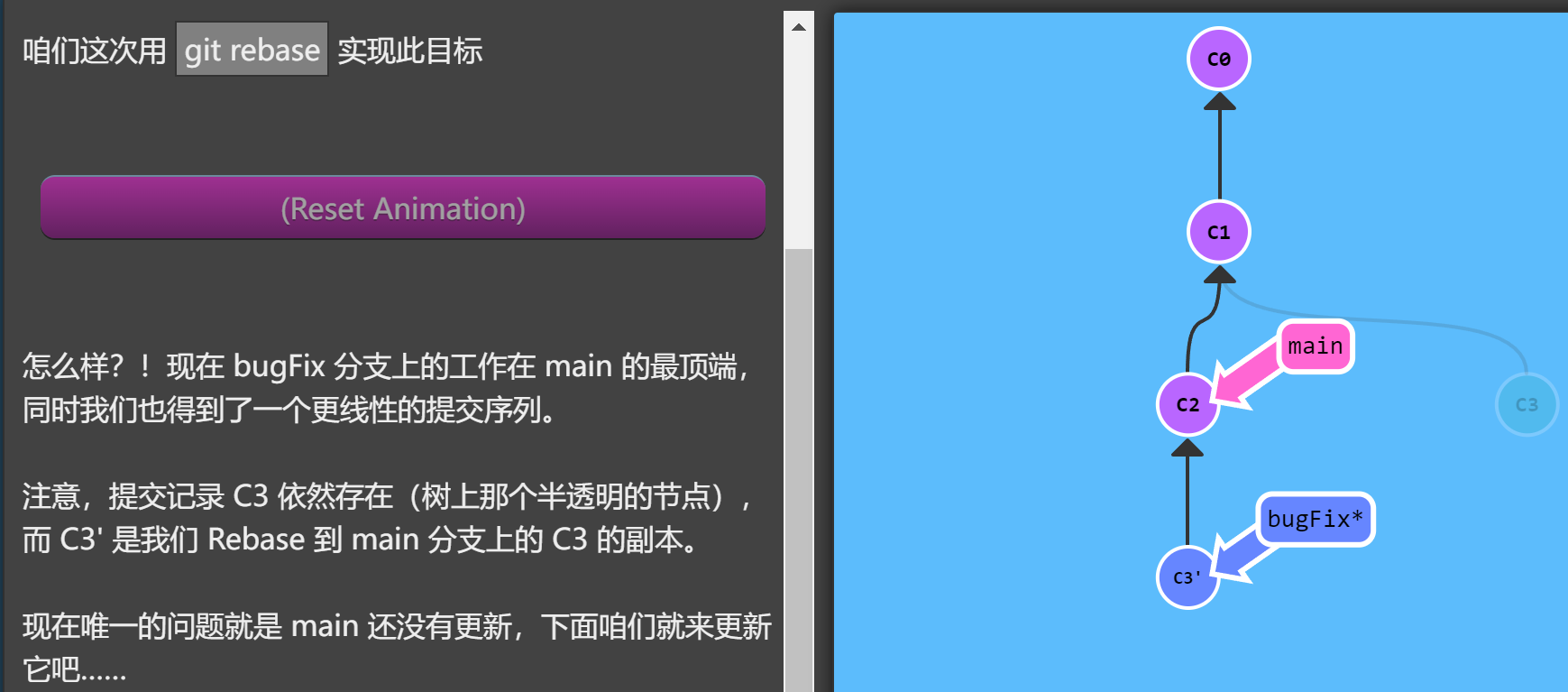
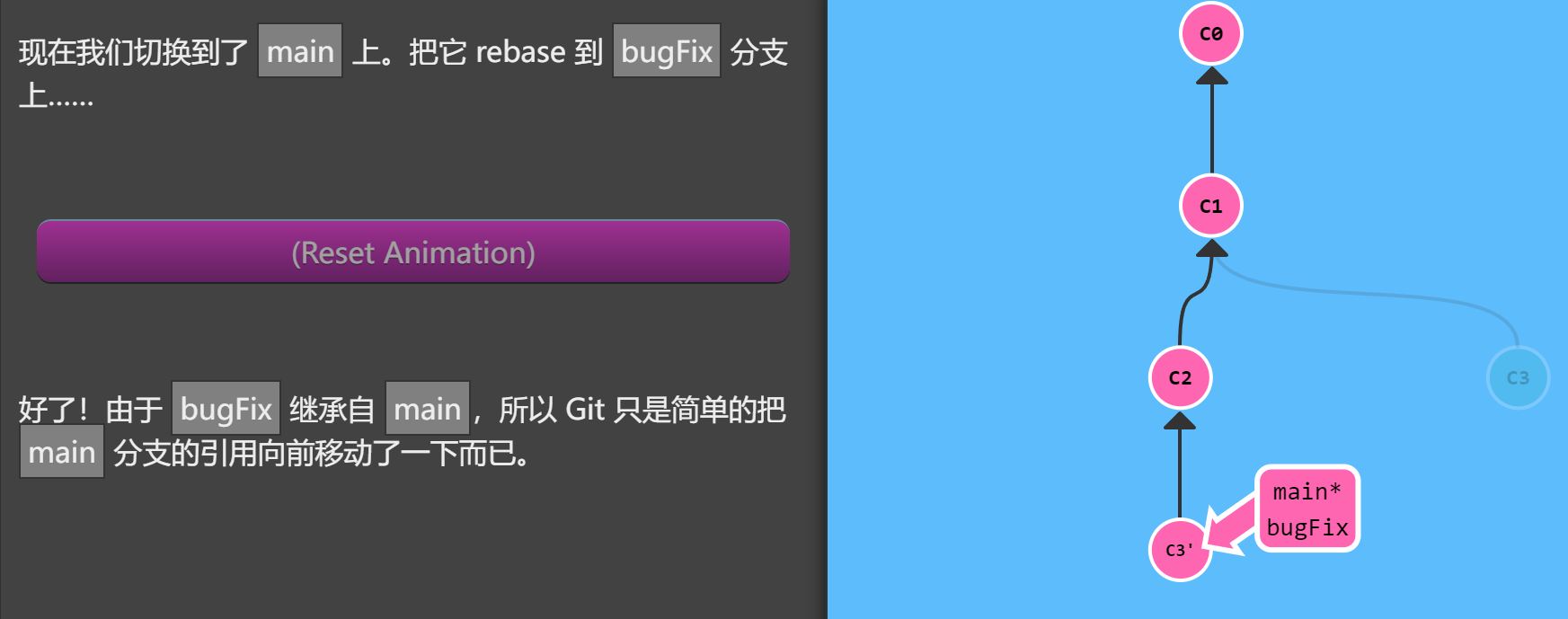
rebase 第二个参数是要移动的源分支,如果不提供默认为 HEAD。如果当前分支不在源分支上,使用第二个参数可以节省一次 checkout 动作。
在提交树上移动
HEAD:你目前正在工作的提交记录,一般指向当前分支的最近一次提交记录,但有时候checkout或者别的原因也可能导致头指针和工作的分支分离,需要查看HEAD的指向可以使用使用cat .git/HEAD命令或者直接使用git branch指令

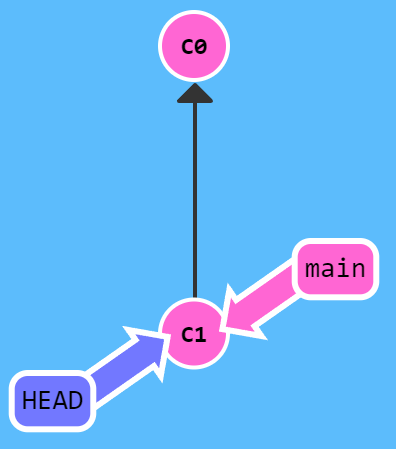
git checkout hashnumber指令的作用即为将目前的头指针指向hashnumber对应的提交,也即执行git checkout C1后,头指针会从main上分离,变为下图的状态
相对引用(^)(~)
Git中提供了一些操作符来引用提交,这样便于我们进行快速的移动头指针而不用随时都列出当前工作区的log来checkout过去。相对引用非常给力,这里我介绍两个简单的用法:
- 使用
^向上移动 1 个提交记录 - 使用
~<num>向上移动多个提交记录,如~3
首先看看操作符 (^)。把这个符号加在引用名称的后面,表示让 Git 寻找指定提交记录的 parent 提交。
所以 main^ 相当于“main 的 parent 节点”,main^^ 是 main 的第二个 parent 节点。我们也可以将 HEAD 作为相对引用的参照,将头指针相对自己往上移动一定的位置。
如果你想在提交树中向上移动很多步的话,敲那么多 ^ 貌似也挺烦人的,Git 当然也考虑到了这一点,于是又引入了操作符 ~。
该操作符后面可以跟一个数字(可选,不跟数字时与 ^ 相同,向上移动一次),指定向上移动多少次。
git branch -f 强制修改分支位置
我使用相对引用最多的就是移动分支。可以直接使用 -f 选项让分支指向另一个提交。例如:
1 | git branch -f main HEAD~3 |
上面的命令会将 main 分支强制指向 HEAD 的第 3 级 parent 提交。
也可以直接使用绝对引用,将分支切换到某个特定提交,但是在切换前一般会要保存工作区的内容,并且移动有时候也会有比较多的冲突之类的问题因此需要最好不要将该分支直接移动到另外的分支中某个与要移动的分支不重合的提交前,也即对于下图而言最好不用使用如下命令,建议多建分支。
1 | git branch -f main C3 |
1 | // 查看日志 |
撤销变更
可以通过 Reset 和 Revert 撤销变更。
git reset
Reset 相当于撤销历史。通过它可以回退本地的提交节点。但是无法处理远程分支。
Revert 用于撤销远程提交。这个过程引入了新的提交节点,因为这个节点做的事情是撤销上个提交节点的内容,所以和上上个节点的内容是一样的。
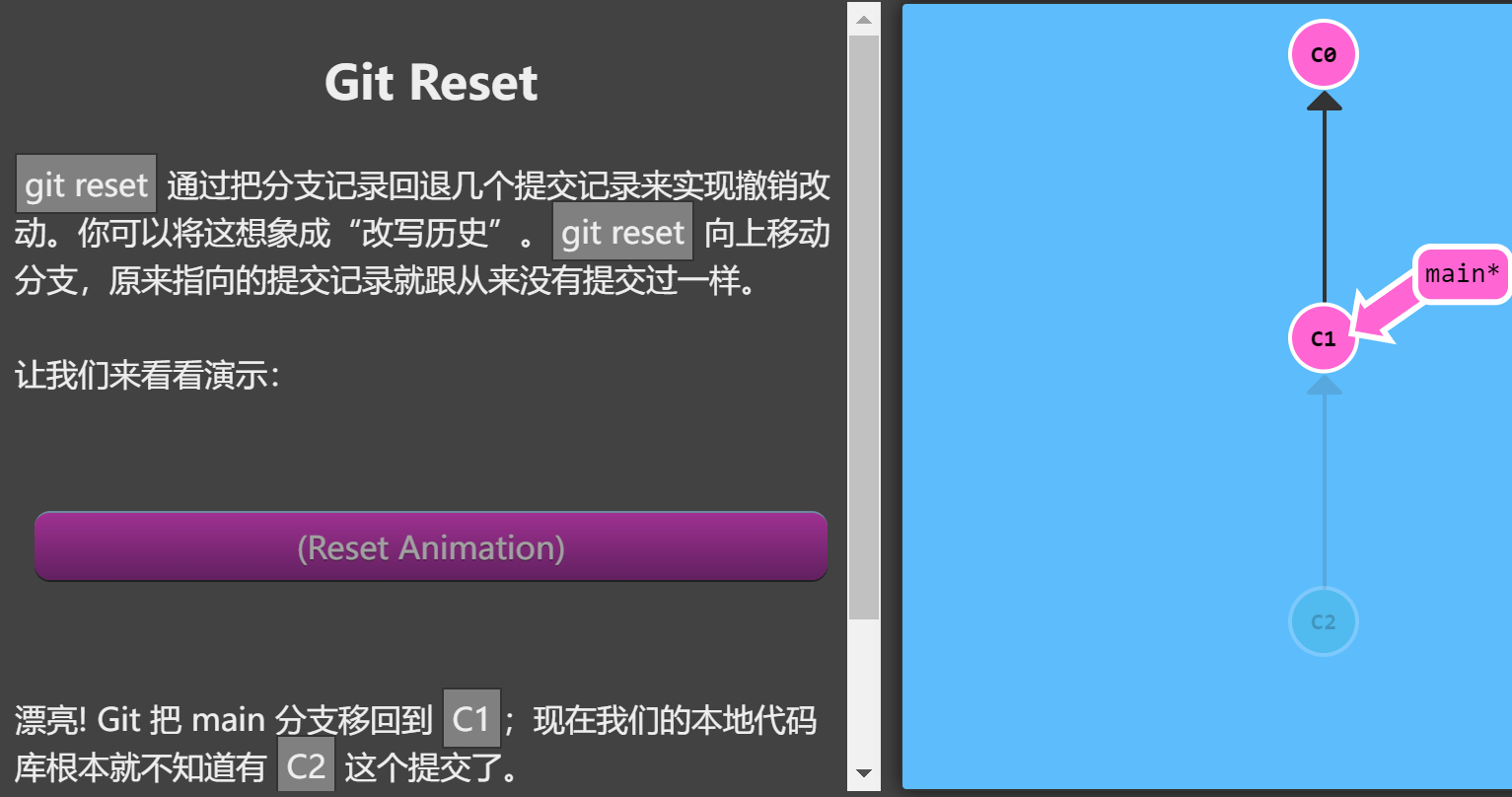
虽然在你的本地分支中使用 git reset 很方便,但是这种“改写历史”的方法对大家一起使用的远程分支是无效的哦!
git revert
为了撤销更改并分享给别人,我们需要使用 git revert。
在我们输入指令git revert C2后要撤销的提交记录后面多了一个新提交!这是因为新提交记录 C2' 引入了更改 —— 这些更改刚好是用来撤销 C2 这个提交的。也就是说 C2' 的状态与 C1 是相同的。
revert 之后就可以把你的更改推送到远程仓库与别人分享啦。
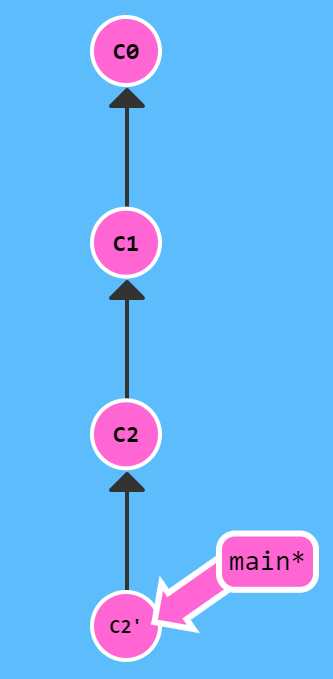
PS:事实上,我们在本地使用revert撤销提交一般较少,为了保证更清晰的提交线,我们一般是在云端进行revert,本地如果要对上一次修改进行重新修改的话直接git commit --amend就行,对于云端已merge的提交要再次进行修改,最好的做法是提交一个新的提交来修复上次提交存在的问题而不是revert,因为当你reverse 再commit后就会存在两个提交需要审核再合入,因此会多一个提交的审核量,所以更建议使用新提交来修复
变更提交顺序
git cherry-pick
Cherry-pick 可以用于将指定提交节点复制到 HEAD 分支上,它的命令的格式如下
git cherry-pick <提交号>...
如果你想将一些提交复制到当前所在的位置(HEAD)下面的话, Cherry-pick 是最直接的方式了。
PS:如果你cherry-pick的是一个云端的未合并的提交,你在本地进行开发后再提交会将这个未合并的提交再commit一遍,这个提交的uploader就变成你了
交互式rebase
当你知道你所需要的提交记录(并且还知道这些提交记录的哈希值)时, 用 cherry-pick 再好不过了 —— 没有比这更简单的方式了。
但是如果你不清楚你想要的提交记录的哈希值呢? 或者你想要再修改前面的提交呢?幸好 Git 帮你想到了这一点, 我们可以利用交互式的 rebase —— 如果你想从一系列的提交记录中找到想要的记录, 这就是最好的方法了
交互式 rebase 指的是使用带参数 --interactive 的 rebase 命令, 简写为 -i
如果你在命令后增加了这个选项, Git 会打开一个 UI 界面并列出将要被复制到目标分支的备选提交记录,它还会显示每个提交记录的哈希值和提交说明,提交说明有助于你理解这个提交进行了哪些更改。
在实际使用时,所谓的 UI 窗口一般会在文本编辑器 —— 如 Vim —— 中打开一个文件。
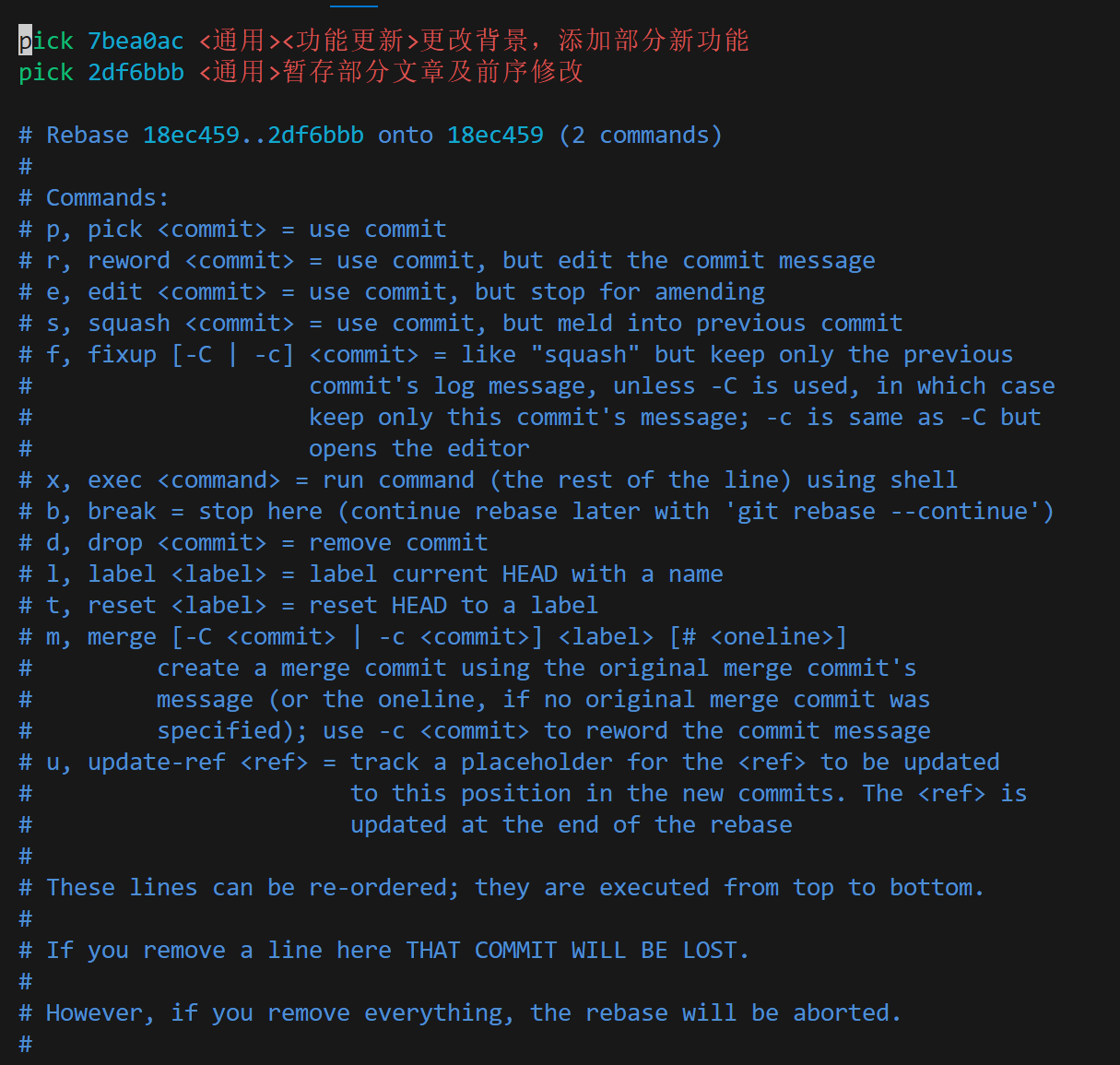
下图为我的博客中使用指令git rebase -i HEAD~2得到的交互式指令界面,我们要调整提交的顺序就可以通过这里pick的顺序来修改,其他的指令如下图所示。
-
pick:保留该 commit
-
reword:保留该 commit,但我需要修改该 commit 的注释
-
edit:保留该 commit,但我要停下来修改该提交(不禁惊修改注释)
-
squash:将该 commit 和前一个 commit 合并
-
fixup:将该 commit 和前一个 commit 合并,但我不要保留该提交的注释信息
-
exec:执行 shell 命令
-
drop:我要丢弃该 commit
当 rebase UI界面打开时, 你能做3件事:
- 调整提交记录的顺序(通过鼠标拖放来完成)
- 删除你不想要的提交(通过切换
pick的状态来完成,关闭就意味着你不想要这个提交记录) - 合并提交。 它允许你把多个提交记录合并成一个。
一些技巧
截取单次提交
来看两个在开发中经常会遇到的情况:
1.我正在解决某个特别棘手的 Bug,为了便于调试而在代码中添加了一些调试命令并向控制台打印了一些信息,这些调试和打印语句都在它们各自的提交记录里,最后我终于找到了造成这个 Bug 的根本原因,解决掉以后觉得沾沾自喜!
最后就差把 bugFix 分支里的工作合并回 main 分支了。你可以选择通过 fast-forward 快速合并到 main 分支上,但这样的话 main 分支就会包含我这些调试语句了。你肯定不想这样,应该还有更好的方式……实际我们只要让 Git 复制解决问题的那一个提交记录就可以了。跟之前我们在“整理提交记录”中学到的一样,我们可以使用git rebase -i git cherry-pick来达到目的。
使用git rebase -i时将某几个提交放弃,就会只保留最新的提交
在原分支cherry-pick某个提交即可只保留该提交
2.当我们一次性提交了5个提交,后三个提交已经merge,而第二个提交需要有新的修改时
我们就可以使用git rebase -i HEAD~4指令,然后将顶部的我们要修改的提交改为edit状态,然后修改后使用git add+git commit --amend再使用git rebase --continue回到最新的工作区
提交的技巧
git rebase
接下来这种情况也是很常见的:你之前在 newImage 分支上进行了一次提交,然后又基于它创建了 caption 分支,然后又提交了一次。
此时你想对某个以前的提交记录进行一些小小的调整。比如设计师想修改一下 newImage 中图片的分辨率,尽管那个提交记录并不是最新的了。
我们可以通过下面的方法来克服困难:
- 用 git rebase -i 将提交重新排序,然后把我们想要修改的提交记录挪到最前
- 用 git commit --amend 来进行一些小修改
- 用 git rebase -i 来将他们调回原来的顺序
- 把 main 移到修改的最前端(用你自己喜欢的方法),就大功告成啦!
或者觉得调整顺序麻烦的话,我们也可以按下列步骤修改
- 用 git rebase -i 打开交互界面,将我们要修改的提交状态改为edit
- 修改然后使用git add 和 git commit --amend的连招
- 使用git rebase --continue将当前指针移动到最前,大功告成
git cherry-pick
我们可以使用 rebase -i 对提交记录进行重新排序。只要把我们想要的提交记录挪到最前端,我们就可以很轻松的用 --amend 修改它,然后把它们重新排成我们想要的顺序。
但这样做就唯一的问题就是要进行两次排序,而这有可能造成由 rebase 而导致的冲突。
使用git cherry-pick 就可以避免一些这些问题,我们使用cherry-pick时会把某个分支上的某个提交拉到我们当前分支的最新提交处,为避免本地和云端冲突,比较好的做法是使用一个Develop分支来作为与云端保持同步的分支,当我们需要cherry-pick某个关系比较复杂的提交时,我们就可以先checkout到这个Develop分支来使用git pull拉取最新的代码,然后再使用git checkout -b bugFix建立一个bugFix分支来进行我们的修改,此时我们就可以在bugFix这个分支上使用cherry-pick拉取要修改的那个提交到最新当前分支处,修改然后使用git add 和 git commit --amend的连招,此时就可以进行push而不存在冲突了
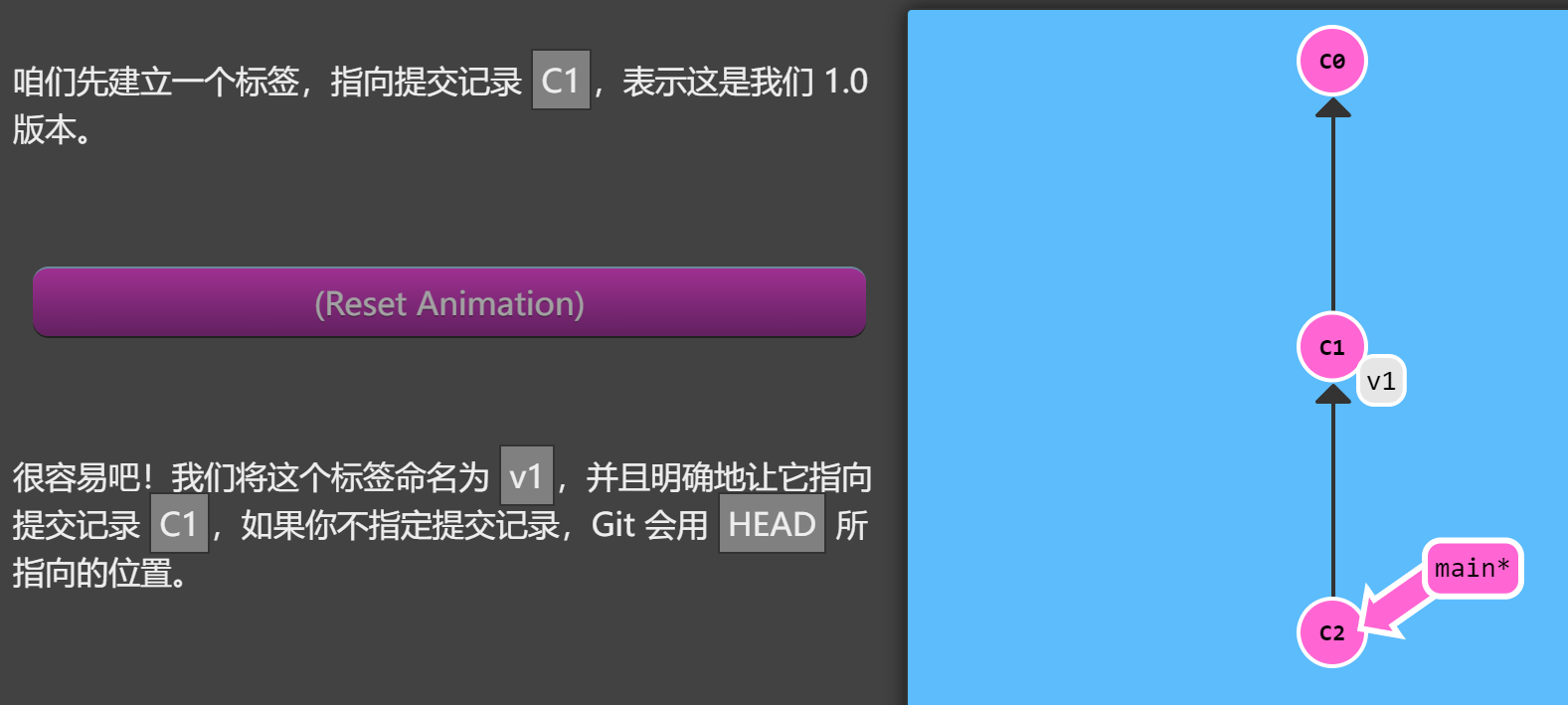
git tag
分支很容易被人为移动,并且当有新的提交时,它也会移动。分支很容易被改变,大部分分支还只是临时的,并且还一直在变。
你可能会问了:有没有什么可以永远指向某个提交记录的标识呢,比如软件发布新的大版本,或者是修正一些重要的 Bug 或是增加了某些新特性,有没有比分支更好的可以永远指向这些提交的方法呢?
当然有了!Git 的 tag 就是干这个用的啊,它们可以(在某种程度上 —— 因为标签可以被删除后重新在另外一个位置创建同名的标签)永久地将某个特定的提交命名为里程碑,然后就可以像分支一样引用了。
更难得的是,它们并不会随着新的提交而移动。你也不能切换到某个标签上面进行修改提交,它就像是提交树上的一个锚点,标识了某个特定的位置。
git describe
由于标签在代码库中起着“锚点”的作用,Git 还为此专门设计了一个命令用来描述离你最近的锚点(也就是标签),它就是 git describe!
Git Describe 能帮你在提交历史中移动了多次以后找到方向;当你用 git bisect(一个查找产生 Bug 的提交记录的指令)找到某个提交记录时,或者是当你坐在你那刚刚度假回来的同事的电脑前时, 可能会用到这个命令。
git describe 的语法是:
1 | git describe <ref> |
<ref> 可以是任何能被 Git 识别成提交记录的引用,如果你没有指定的话,Git 会使用你目前所在的位置(HEAD)。
它输出的结果是这样的:
1 | <tag>_<numCommits>_g<hash> |
tag 表示的是离 ref 最近的标签, numCommits 是表示这个 ref 与 tag 相差有多少个提交记录, hash 表示的是你所给定的 ref 所表示的提交记录哈希值的前几位。
当 ref 提交记录上有某个标签时,则只输出标签名称

多分支rebase
git rebase side2 side1操作会将当前side1的所有和side2有分支差异且可合并的提交合并到side2的提交上并将HEAD移动到side1上
选择 parent 提交记录
操作符 ^ 与 ~ 符一样,后面也可以跟一个数字。
但是该操作符后面的数字与 ~ 后面的不同,并不是用来指定向上返回几代,而是指定合并提交记录的某个 parent 提交。还记得前面提到过的一个合并提交有两个 parent 提交吧,所以遇到这样的节点时该选择哪条路径就不是很清晰了。
Git 默认选择合并提交的“第一个” parent 提交,在操作符 ^ 后跟一个数字可以改变这一默认行为。
纠缠不清的分支
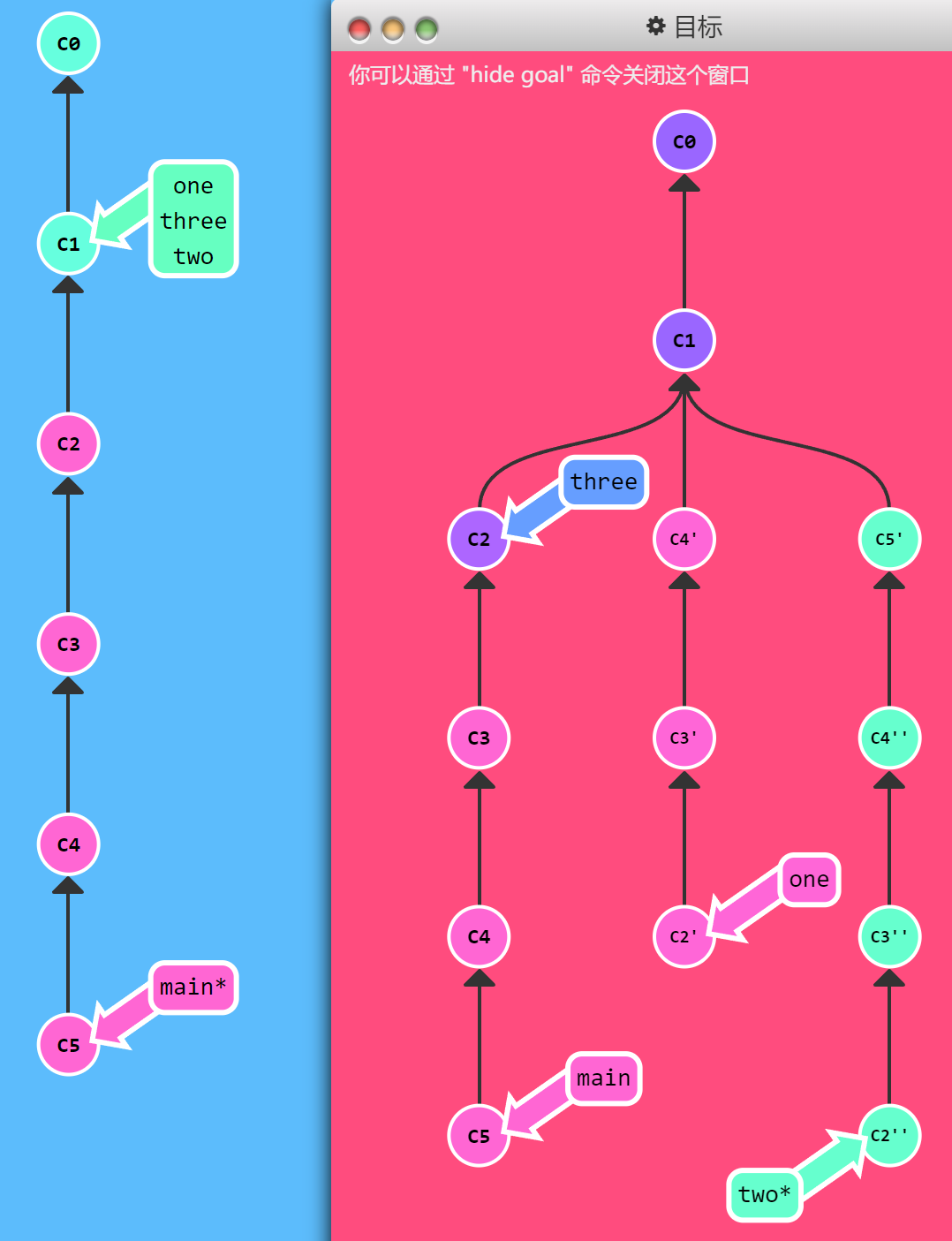
现在我们的 main 分支是比 one、two 和 three 要多几个提交。出于某种原因,我们需要把 main 分支上最近的几次提交做不同的调整后,分别添加到各个的分支上。
one 需要重新排序并删除 C5,two 仅需要重排排序,而 three 只需要提交一次。
1 | git checkout one |
Git 云端仓库
远程仓库
远程仓库并不复杂, 在如今的云计算盛行的世界很容易把远程仓库想象成一个富有魔力的东西, 但实际上它们只是你的仓库在另个一台计算机上的拷贝。你可以通过因特网与这台计算机通信 —— 也就是增加或是获取提交记录
话虽如此, 远程仓库却有一系列强大的特性
- 首先也是最重要的的点, 远程仓库是一个强大的备份。本地仓库也有恢复文件到指定版本的能力, 但所有的信息都是保存在本地的。有了远程仓库以后,即使丢失了本地所有数据, 你仍可以通过远程仓库拿回你丢失的数据。
- 还有就是, 远程让代码社交化了! 既然你的项目被托管到别的地方了, 你的朋友可以更容易地为你的项目做贡献(或者拉取最新的变更)
现在用网站来对远程仓库进行可视化操作变得越发流行了(像 GitHub), 但远程仓库永远是这些工具的顶梁柱, 因此理解其概念非常的重要!
我们现在需要学习远程仓库的操作 —— 我们需要一个配置这种环境的命令, 它就是 git clone。 从技术上来讲,git clone 命令在真实的环境下的作用是在本地创建一个远程仓库的拷贝(比如从 github.com)。
使用git clone 命令完成对远程仓库和本地仓库的建立,咱们深入地看一下发生了什么。
你可能注意到的第一个事就是在我们的本地仓库多了一个名为 origin/main 的分支, 这种类型的分支就叫远程分支。由于远程分支的特性导致其拥有一些特殊属性。
远程分支反映了远程仓库(在你上次和它通信时)的状态。这会有助于你理解本地的工作与公共工作的差别 —— 这是你与别人分享工作成果前至关重要的一步.
远程分支有一个特别的属性,在你切换到远程分支时,自动进入分离 HEAD 状态。Git 这么做是出于不能直接在这些分支上进行操作的原因, 你必须在别的地方完成你的工作, (更新了远程分支之后)再用远程分享你的工作成果。
为什么有 origin/?
你可能想问这些远程分支的前面的 origin/ 是什么意思呢?远程分支有一个命名规范 —— 它们的格式是:
<remote name>/<branch name>
因此,如果你看到一个名为 origin/main 的分支,那么这个分支就叫 main,远程仓库的名称就是 origin。
大多数的开发人员会将它们主要的远程仓库命名为 origin,这是因为当你用 git clone 某个仓库时,Git 已经帮你把远程仓库的名称设置为 origin 了
如果切换到远程分支会怎么样呢?
Git 变成了分离 HEAD 状态,当添加新的提交时 o/main 也不会更新。这是因为 o/main 只有在远程仓库中相应的分支更新了以后才会更新。
Git Fetch
Git 远程仓库相当的操作实际可以归纳为两点:向远程仓库传输数据以及从远程仓库获取数据。既然我们能与远程仓库同步,那么就可以分享任何能被 Git 管理的更新(因此可以分享代码、文件、想法、情书等等)。
本节课我们将学习如何从远程仓库获取数据 —— 命令如其名,它就是 git fetch。
你会看到当我们从远程仓库获取数据时, 远程分支也会更新以反映最新的远程仓库。
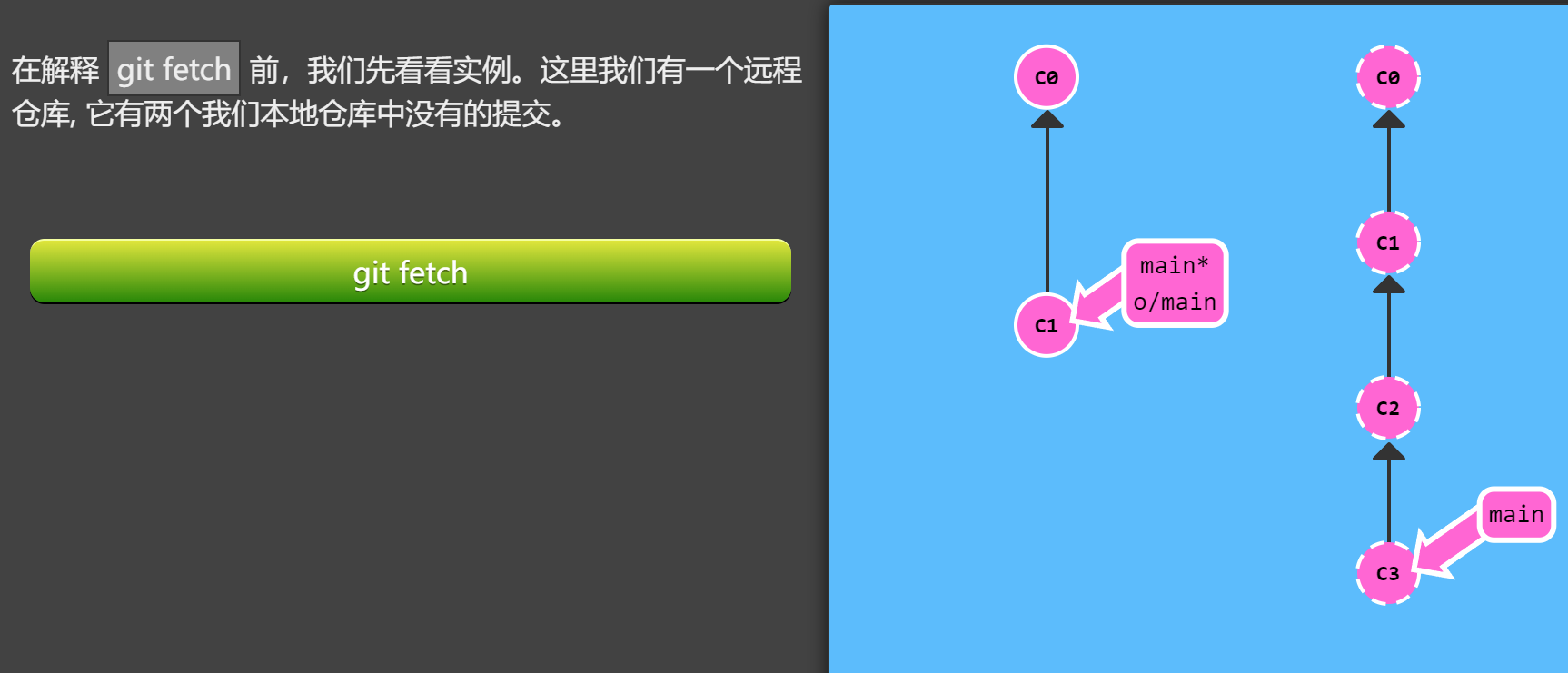

git fetch 做了些什么
git fetch 完成了仅有的但是很重要的两步:
- 从远程仓库下载本地仓库中缺失的提交记录
- 更新远程分支指针(如
o/main)
git fetch 实际上将本地仓库中的远程分支更新成了远程仓库相应分支最新的状态。
如果你还记得上一节课程中我们说过的,远程分支反映了远程仓库在你最后一次与它通信时的状态,git fetch 就是你与远程仓库通信的方式了!希望我说的够明白了,你已经了解 git fetch 与远程分支之间的关系了吧。
git fetch 通常通过互联网(使用 http:// 或 git:// 协议) 与远程仓库通信。
git fetch 不会做的事
git fetch 并不会改变你本地仓库的状态。它不会更新你的 main 分支,也不会修改你磁盘上的文件。
理解这一点很重要,因为许多开发人员误以为执行了 git fetch 以后,他们本地仓库就与远程仓库同步了。它可能已经将进行这一操作所需的所有数据都下载了下来,但是并没有修改你本地的文件。我们在后面的课程中将会讲解能完成该操作的命令 😄
所以, 你可以将 git fetch 的理解为单纯的下载操作。
Git Pull
既然我们已经知道了如何用 git fetch 获取远程的数据, 现在我们学习如何将这些变化更新到我们的工作当中。
其实有很多方法的 —— 当远程分支中有新的提交时,你可以像合并本地分支那样来合并远程分支。也就是说就是你可以执行以下命令:
git cherry-pick o/maingit rebase o/maingit merge o/main- 等等
实际上,由于先抓取更新再合并到本地分支这个流程很常用,因此 Git 提供了一个专门的命令来完成这两个操作。它就是我们要讲的 git pull。
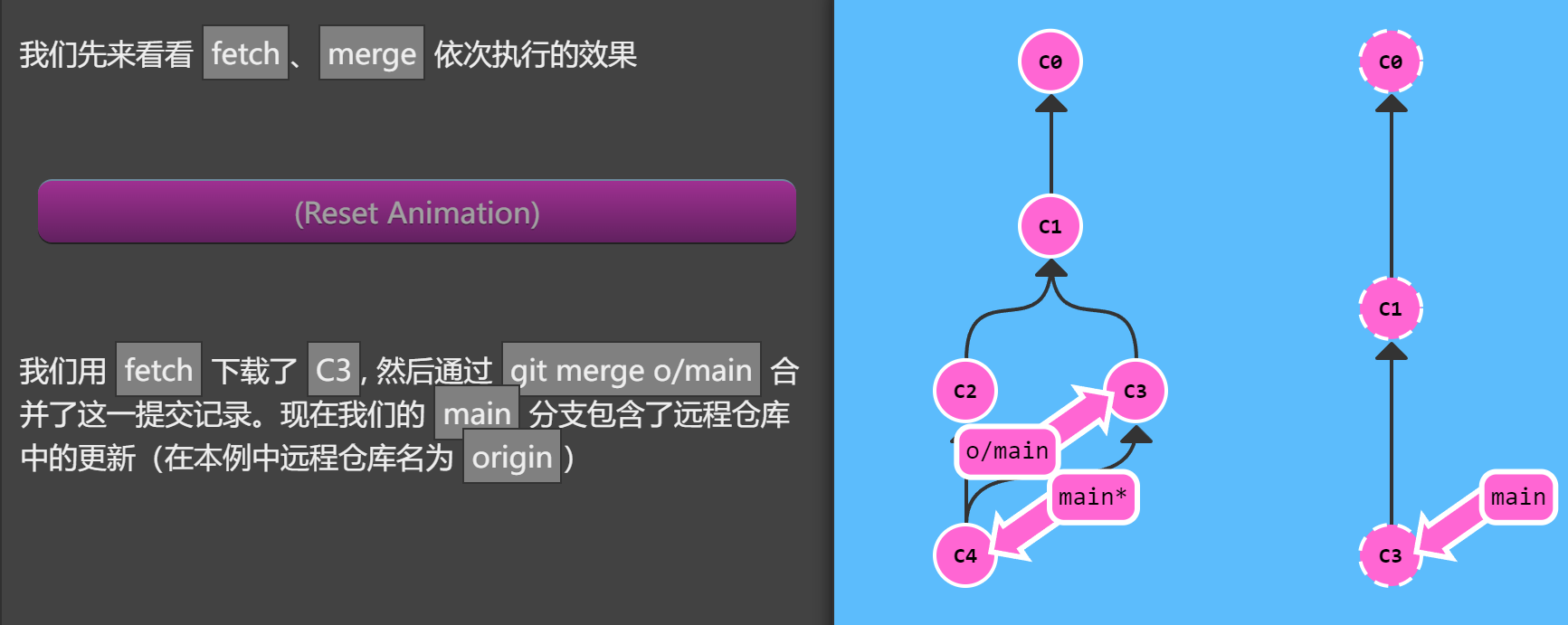
事实上,git pull 就是 git fetch 和 git merge 的缩写!
Git Push
git push 负责将你的变更上传到指定的远程仓库,并在远程仓库上合并你的新提交记录。一旦 git push 完成, 你的朋友们就可以从这个远程仓库下载你分享的成果了!
你可以将 git push 想象成发布你成果的命令。它有许多应用技巧,稍后我们会了解到,但是咱们还是先从基础的开始吧……
注意 —— git push 不带任何参数时的行为与 Git 的一个名为 push.default 的配置有关。它的默认值取决于你正使用的 Git 的版本,但是在教程中我们使用的是 upstream。 这没什么太大的影响,但是在你的项目中进行推送之前,最好检查一下这个配置。
偏离的工作
现在我们已经知道了如何从其它地方 pull 提交记录,以及如何 push 我们自己的变更。看起来似乎没什么难度,但是为何还会让人们如此困惑呢?
困难来自于远程库提交历史的偏离。在讨论这个问题的细节前,我们先来看一个例子……
假设你周一克隆了一个仓库,然后开始研发某个新功能。到周五时,你新功能开发测试完毕,可以发布了。但是 —— 天啊!你的同事这周写了一堆代码,还改了许多你的功能中使用的 API,这些变动会导致你新开发的功能变得不可用。但是他们已经将那些提交推送到远程仓库了,因此你的工作就变成了基于项目旧版的代码,与远程仓库最新的代码不匹配了。
这种情况下, git push 就不知道该如何操作了。如果你执行 git push,Git 应该让远程仓库回到星期一那天的状态吗?还是直接在新代码的基础上添加你的代码,亦或由于你的提交已经过时而直接忽略你的提交?
因为这情况(历史偏离)有许多的不确定性,Git 是不会允许你 push 变更的。实际上它会强制你先合并远程最新的代码,然后才能分享你的工作。
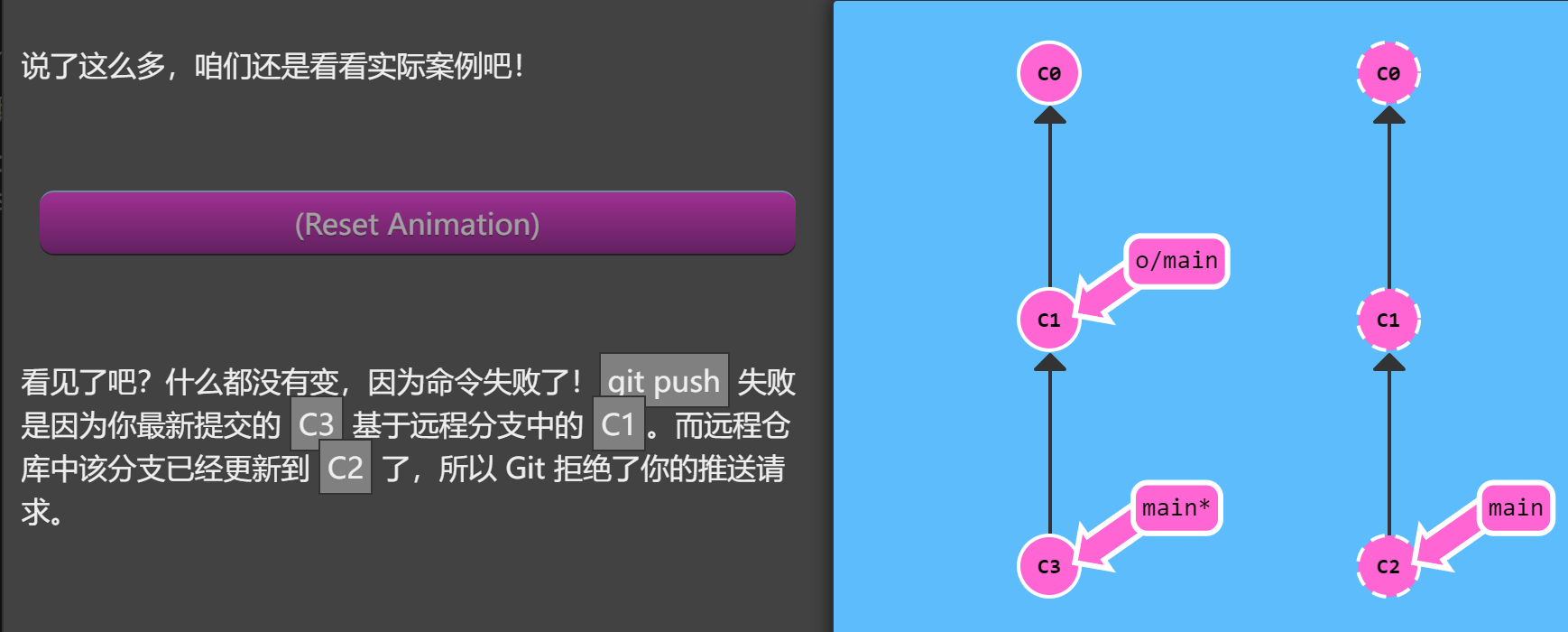
那该如何解决这个问题呢?很简单,你需要做的就是使你的工作基于最新的远程分支。
有许多方法做到这一点呢,不过最直接的方法就是通过 rebase 调整你的工作。咱们继续,看看怎么 rebase!
1 | git fetch |
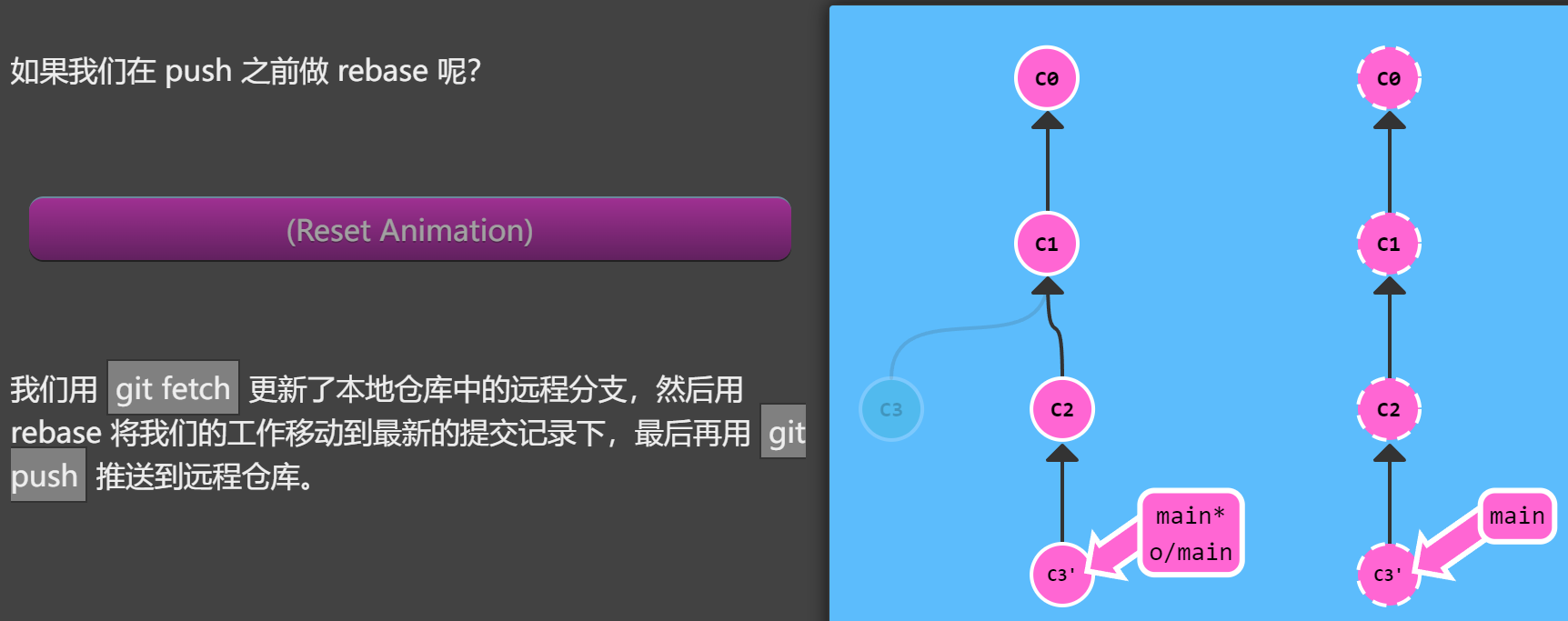
还有其它的方法可以在远程仓库变更了以后更新我的工作吗? 当然有,我们还可以使用 merge
尽管 git merge 不会移动你的工作(它会创建新的合并提交),但是它会告诉 Git 你已经合并了远程仓库的所有变更。这是因为远程分支现在是你本地分支的祖先,也就是说你的提交已经包含了远程分支的所有变化。
看下演示…
1 | git fetch |
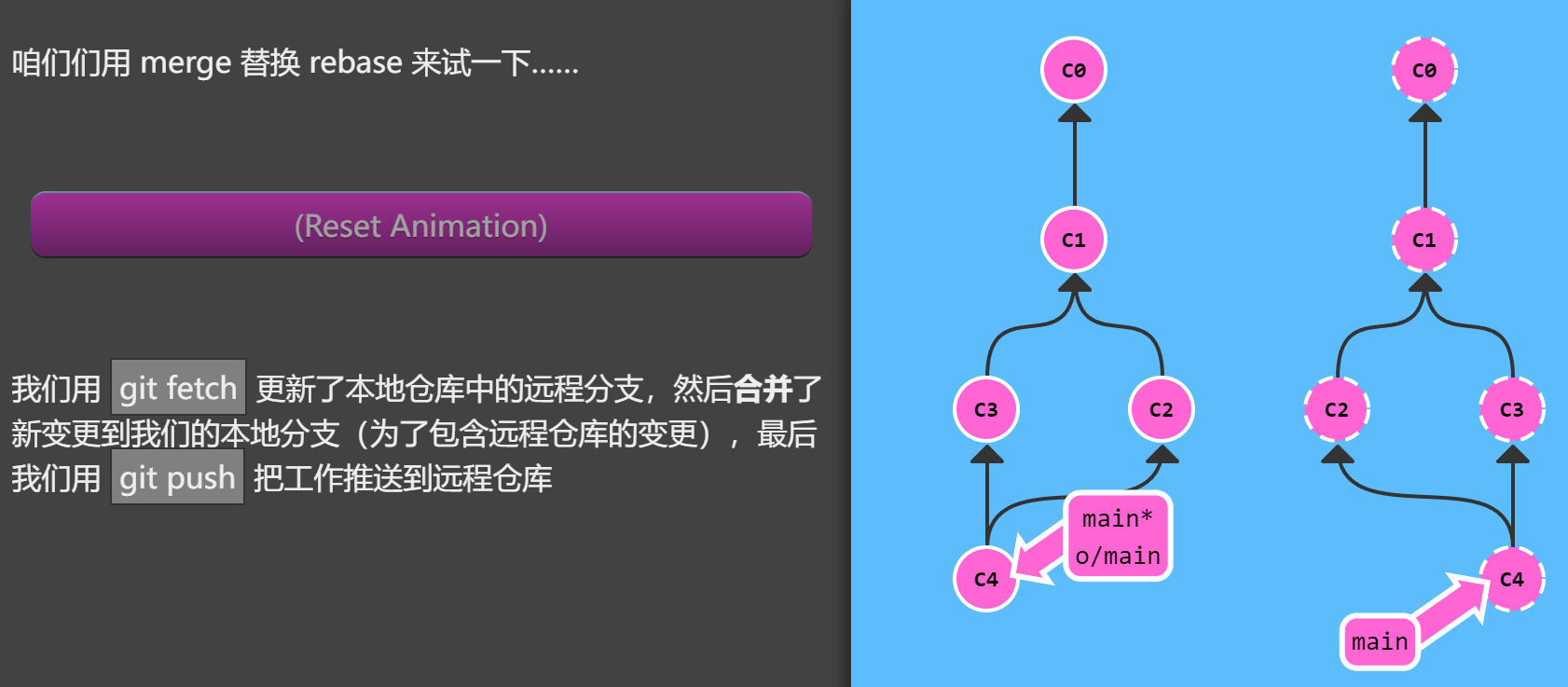
事实上,因为merge会多一个单独的C4的提交,对于公司的开发而言,有很多需要审核的地方, 所以不要添加这个merge的提交,最好的方式就是rebase。
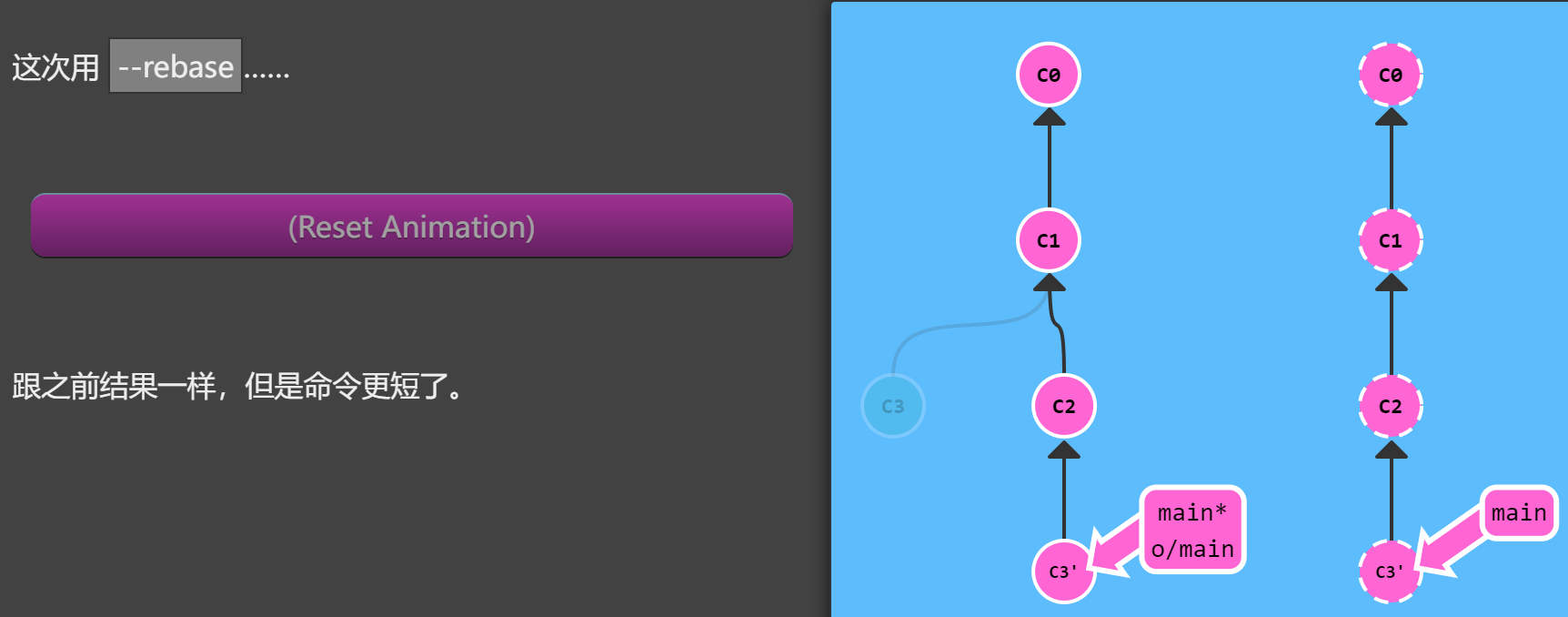
很好!但是要敲那么多命令,有没有更简单一点的?
当然 —— 前面已经介绍过 git pull 就是 fetch 和 merge 的简写,类似的 git pull --rebase 就是 fetch 和 rebase 的简写!
1 | git pull --rebae |
远程服务器拒绝!(Remote Rejected)
如果你是在一个大的合作团队中工作, 很可能是main被锁定了, 需要一些Pull Request流程来合并修改。如果你直接提交(commit)到本地main, 然后试图推送(push)修改, 你将会收到这样类似的信息:
1 | ! [远程服务器拒绝] main -> main (TF402455: 不允许推送(push)这个分支; 你必须使用pull request来更新这个分支.) |
为什么会被拒绝?
远程服务器拒绝直接推送(push)提交到main, 因为策略配置要求 pull requests 来提交更新.
你应该按照流程,新建一个分支, 推送(push)这个分支并申请pull request,但是你忘记并直接提交给了main.现在你卡住并且无法推送你的更新.
合并特性分支
既然你应该很熟悉 fetch、pull、push 了,现在我们要通过一个新的工作流来测试你的这些技能。
在大型项目中开发人员通常会在(从 main 上分出来的)特性分支上工作,工作完成后只做一次集成。这跟前面课程的描述很相像(把 side 分支推送到远程仓库),不过本节我们会深入一些.
但是有些开发人员只在 main 上做 push、pull —— 这样的话 main 总是最新的,始终与远程分支 (o/main) 保持一致。
对于接下来这个工作流,我们集成了两个步骤:
- 将特性分支集成到
main上 - 推送并更新远程分支
接下来的关卡建议全部都到网站实操一下,能学到很多
1 | git fetch |
为什么不用 merge 呢?
为了 push 新变更到远程仓库,你要做的就是包含远程仓库中最新变更。意思就是只要你的本地分支包含了远程分支(如 o/main)中的最新变更就可以了,至于具体是用 rebase 还是 merge,并没有限制。
那么既然没有规定限制,为何前面几节都在着重于 rebase 呢?为什么在操作远程分支时不喜欢用 merge 呢
在开发社区里,有许多关于 merge 与 rebase 的讨论。以下是关于 rebase 的优缺点:
优点:
- Rebase 使你的提交树变得很干净, 所有的提交都在一条线上
缺点:
- Rebase 修改了提交树的历史
比如, 提交 C1 可以被 rebase 到 C3 之后。这看起来 C1 中的工作是在 C3 之后进行的,但实际上是在 C3 之前。
一些开发人员喜欢保留提交历史,因此更偏爱 merge。而其他人(比如我自己)可能更喜欢干净的提交树,于是偏爱 rebase。仁者见仁,智者见智。 😄
1 | git checkout main |
远程跟踪分支
在前几节课程中有件事儿挺神奇的,Git 好像知道 main 与 o/main 是相关的。当然这些分支的名字是相似的,可能会让你觉得是依此将远程分支 main 和本地的 main 分支进行了关联。这种关联在以下两种情况下可以清楚地得到展示:
- pull 操作时, 提交记录会被先下载到 o/main 上,之后再合并到本地的 main 分支。隐含的合并目标由这个关联确定的。
- push 操作时, 我们把工作从
main推到远程仓库中的main分支(同时会更新远程分支o/main) 。这个推送的目的地也是由这种关联确定的!
直接了当地讲,main 和 o/main 的关联关系就是由分支的“remote tracking”属性决定的。main 被设定为跟踪 o/main —— 这意味着为 main 分支指定了推送的目的地以及拉取后合并的目标。
你可能想知道 main 分支上这个属性是怎么被设定的,你并没有用任何命令指定过这个属性呀!好吧, 当你克隆仓库的时候, Git 就自动帮你把这个属性设置好了。
当你克隆时, Git 会为远程仓库中的每个分支在本地仓库中创建一个远程分支(比如 o/main)。然后再创建一个跟踪远程仓库中活动分支的本地分支,默认情况下这个本地分支会被命名为 main。
克隆完成后,你会得到一个本地分支(如果没有这个本地分支的话,你的目录就是“空白”的),但是可以查看远程仓库中所有的分支(如果你好奇心很强的话)。这样做对于本地仓库和远程仓库来说,都是最佳选择。
这也解释了为什么会在克隆的时候会看到下面的输出:
1 | local branch "main" set to track remote branch "o/main" |
我能自己指定这个属性吗?
当然可以啦!你可以让任意分支跟踪 o/main, 然后该分支会像 main 分支一样得到隐含的 push 目的地以及 merge 的目标。 这意味着你可以在分支 totallyNotMain 上执行 git push,将工作推送到远程仓库的 main 分支上。
有两种方法设置这个属性,第一种就是通过远程分支切换到一个新的分支,执行:
1 | git checkout -b totallyNotMain o/main |
就可以创建一个名为 totallyNotMain 的分支,它跟踪远程分支 o/main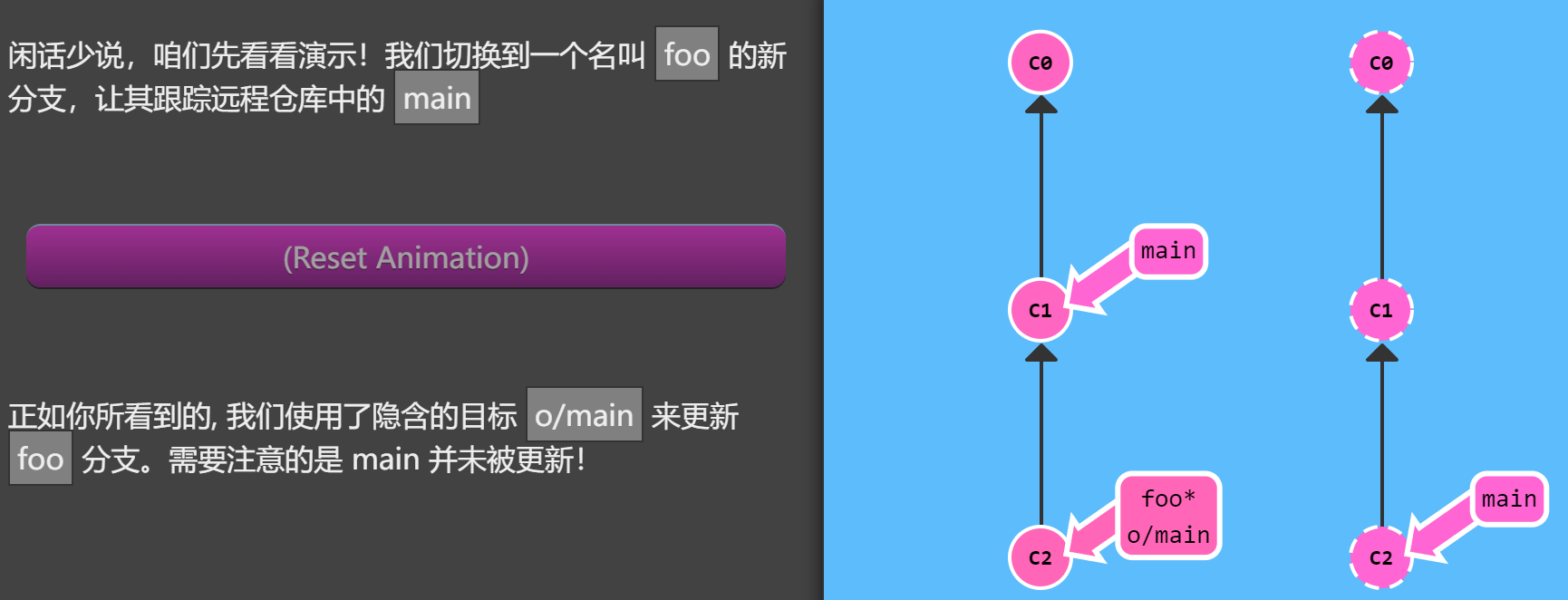
1 | git checkout -b foo o/main |
git push 同样适用
1 | git checkout -b foo o/main |
我们将一个并不叫 main 的分支上的工作推送到了远程仓库中的 main 分支上
第二种方法
另一种设置远程追踪分支的方法就是使用:git branch -u 命令,执行:
1 | git branch -u o/main foo |
这样 foo 就会跟踪 o/main 了。如果当前就在 foo 分支上, 还可以省略 foo:
1 | git branch -u o/main |
Git Push 的参数
很好! 既然你知道了远程跟踪分支,我们可以开始揭开 git push、fetch 和 pull 的神秘面纱了。我们会逐个介绍这几个命令,它们在理念上是非常相似的。
首先来看 git push。在远程跟踪课程中,你已经学到了 Git 是通过当前所在分支的属性来确定远程仓库以及要 push 的目的地的。这是未指定参数时的行为,我们可以为 push 指定参数,语法是:
1 | git push <remote> <place> |
<place> 参数是什么意思呢?我们稍后会深入其中的细节, 先看看例子, 这个命令是:
1 | git push origin main |
把这个命令翻译过来就是:
切到本地仓库中的“main”分支,获取所有的提交,再到远程仓库“origin”中找到“main”分支,将远程仓库中没有的提交记录都添加上去,搞定之后告诉我。
我们通过<place>参数来告诉 Git 提交记录来自于 main, 要推送到远程仓库中的 main。它实际就是要同步的两个仓库的位置。
需要注意的是,因为我们通过指定参数告诉了 Git 所有它需要的信息, 所以它就忽略了我们所切换分支的属性!
<place>参数详解
还记得之前课程说的吧,当为 git push 指定 place 参数为 main 时,我们同时指定了提交记录的来源和去向。
你可能想问 —— 如果来源和去向分支的名称不同呢?比如你想把本地的 foo 分支推送到远程仓库中的 bar 分支。
哎,很遗憾 Git 做不到…… 开个玩笑,别当真!当然是可以的啦 😃 Git 拥有超强的灵活性(有点过于灵活了)
接下来咱们看看是怎么做的……
要同时为源和目的地指定 <place> 的话,只需要用冒号 : 将二者连起来就可以了:
1 | git push origin <source>:<destination> |
这个参数实际的值是个 refspec,“refspec” 是一个自造的词,意思是 Git 能识别的位置(比如分支 foo 或者 HEAD~1)
一旦你指定了独立的来源和目的地,就可以组织出言简意赅的远程操作命令了,让我们看看演示!
记住,source 可以是任何 Git 能识别的位置:
1 | git push origin foo^:main |
这是个令人困惑的命令,但是它确实是可以运行的 —— Git 将 foo^ 解析为一个位置,上传所有未被包含到远程仓库里 main 分支中的提交记录。
如果你要推送到的目的分支不存在会怎么样呢?没问题!Git 会在远程仓库中根据你提供的名称帮你创建这个分支!
Git fetch 的参数
我们刚学习了 git push 的参数,很酷的 <place> 参数,还有用冒号分隔的 refspecs(<source>:<destination>)。 这些参数可以用于 git fetch 吗?
你猜中了!git fetch 的参数和 git push 极其相似。他们的概念是相同的,只是方向相反罢了(因为现在你是下载,而非上传)
让我们逐个讨论下这些概念……
<place> 参数
如果你像如下命令这样为 git fetch 设置 的话:
1 | git fetch origin foo |
Git 会到远程仓库的 foo 分支上,然后获取所有本地不存在的提交,放到本地的 o/foo 上。
来看个例子(还是前面的例子,只是命令不同了)
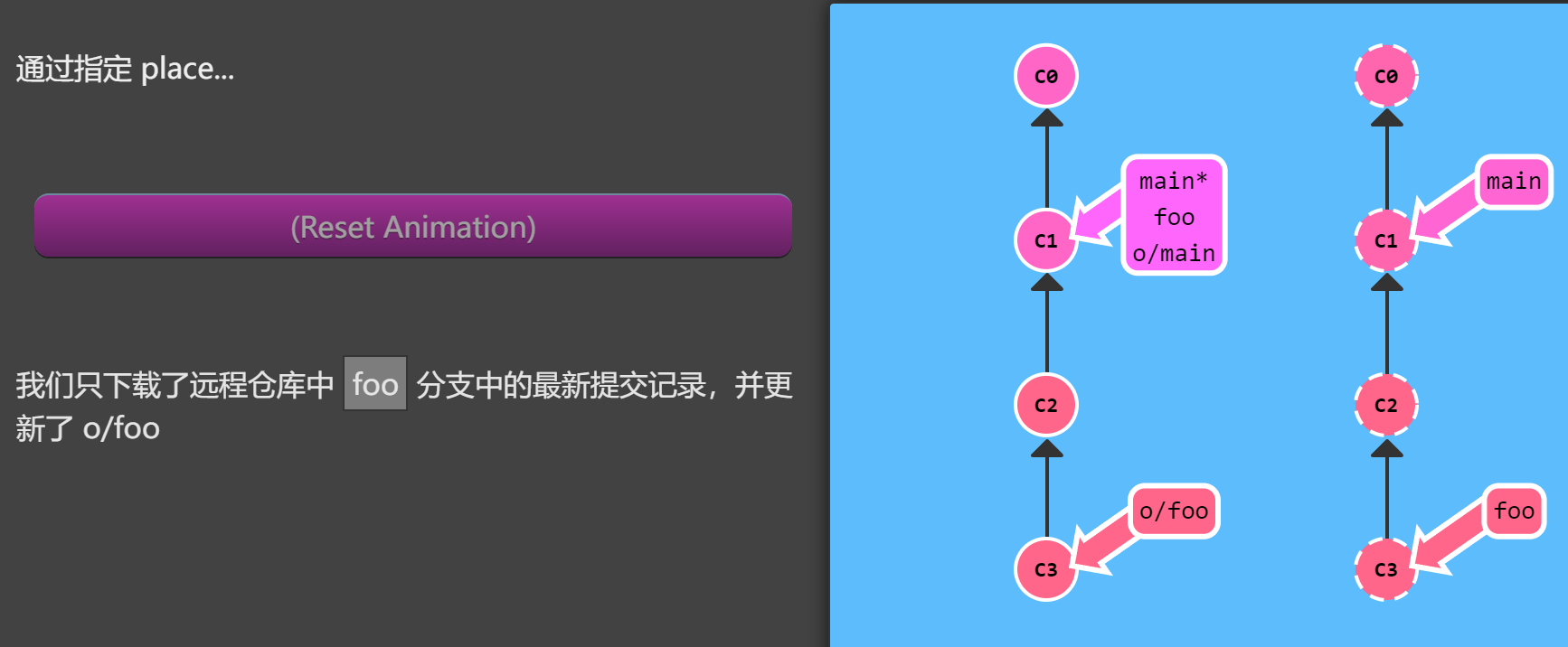
你可能会好奇 —— 为何 Git 会将新提交放到 o/foo 而不是放到我本地的 foo 分支呢?之前不是说这样的 参数就是同时应用于本地和远程的位置吗?
好吧, 本例中 Git 做了一些特殊处理,因为你可能在 foo 分支上的工作还未完成,你也不想弄乱它。还记得在 git fetch 课程里我们讲到的吗 —— 它不会更新你的本地的非远程分支, 只是下载提交记录(这样, 你就可以对远程分支进行检查或者合并了)。
“如果我们指定 <source>:<destination> 会发生什么呢?”
如果你觉得直接更新本地分支很爽,那你就用冒号分隔的 refspec 吧。不过,你不能在当前切换的分支上干这个事,但是其它分支是可以的。
这里有一点是需要注意的 —— source 现在指的是远程仓库中的位置,而 <destination> 才是要放置提交的本地仓库的位置。它与 git push 刚好相反,这是可以讲的通的,因为我们在往相反的方向传送数据。
理论上虽然行的通,但开发人员很少这么做。我在这里介绍它主要是为了从概念上说明 fetch 和 push 的相似性,只是方向相反罢了。
来看个疯狂的例子:
1 | git fetch origin foo~:bar |
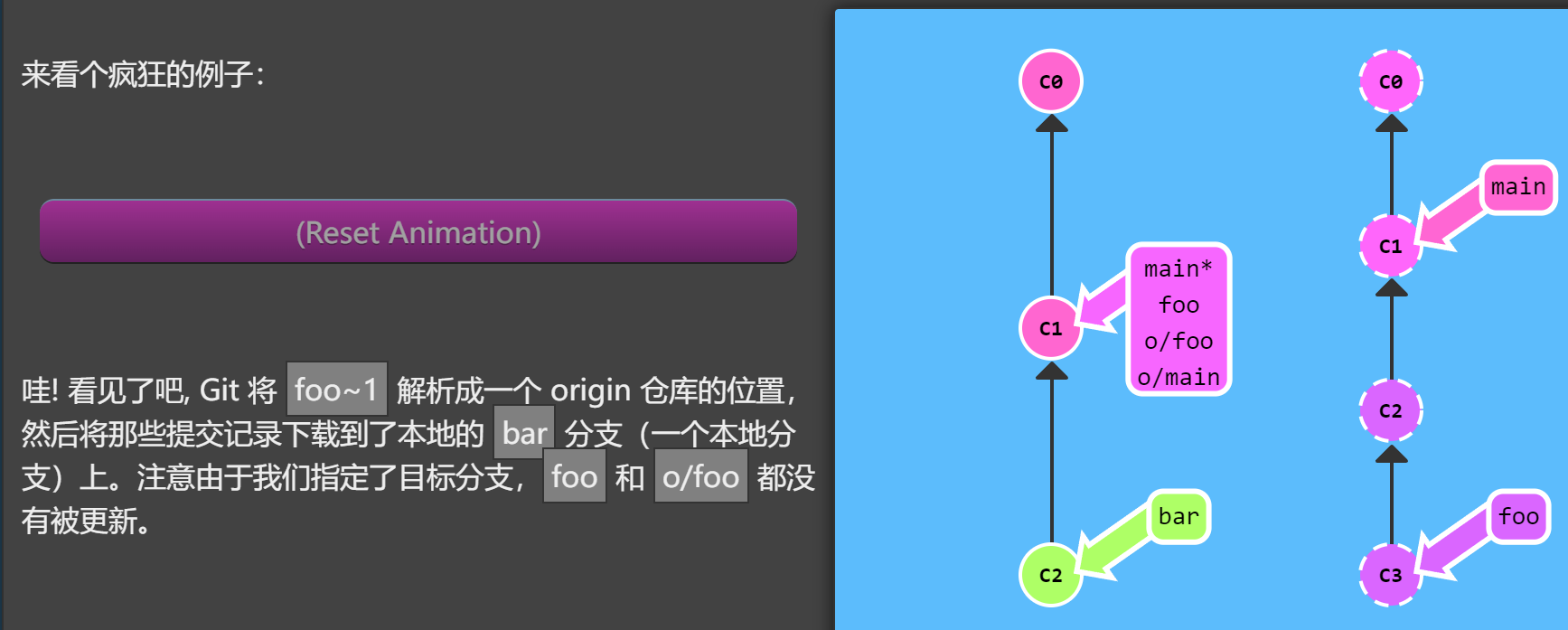
如果执行命令前目标分支不存在会怎样呢?我们看一下上个对话框中没有 bar 分支的情况。
跟 git push 一样,Git 会在 fetch 前自己创建立本地分支, 就像是 Git 在 push 时,如果远程仓库中不存在目标分支,会自己在建立一样。
没有参数呢?
如果 git fetch 没有参数,它会下载所有的提交记录到各个远程分支……
相当简单,但是仅需更新一次,值得你去做!
古怪的 <source>
Git 有两种关于 <source> 的用法是比较诡异的,即你可以在 git push 或 git fetch 时不指定任何 source,方法就是仅保留冒号和 destination 部分,source 部分留空。
git push origin :sidegit fetch origin :bugFix
我们分别来看一下这两条命令的作用……
如果 push 空 到远程仓库会如何呢?它会删除远程仓库中的分支!
1 | git push origin :foo |
就是这样子, 我们通过给 push 传空值 source,成功删除了远程仓库中的 foo 分支, 这真有意思…
如果 fetch 空 到本地,会在本地创建一个新分支。
1 | git fetch origin :bugFix |
很神奇吧!但无论怎么说, 这就是 Git!
Git pull 参数
既然你已经掌握关于 git fetch 和 git push 参数的方方面面了,关于 git pull 几乎没有什么可以讲的了 😃
因为 git pull 到头来就是 fetch 后跟 merge 的缩写。你可以理解为用同样的参数执行 git fetch,然后再 merge 你所抓取到的提交记录。
还可以和其它更复杂的参数一起使用, 来看一些例子:
以下命令在 Git 中是等效的:
git pull origin foo 相当于:
1 | git fetch origin foo; git merge o/foo |
还有…
git pull origin bar~1:bugFix 相当于:
1 | git fetch origin bar~1:bugFix; git merge bugFix |
看到了? git pull 实际上就是 fetch + merge 的缩写, git pull 唯一关注的是提交最终合并到哪里(也就是为 git fetch 所提供的 destination 参数)
一起来看个例子吧:
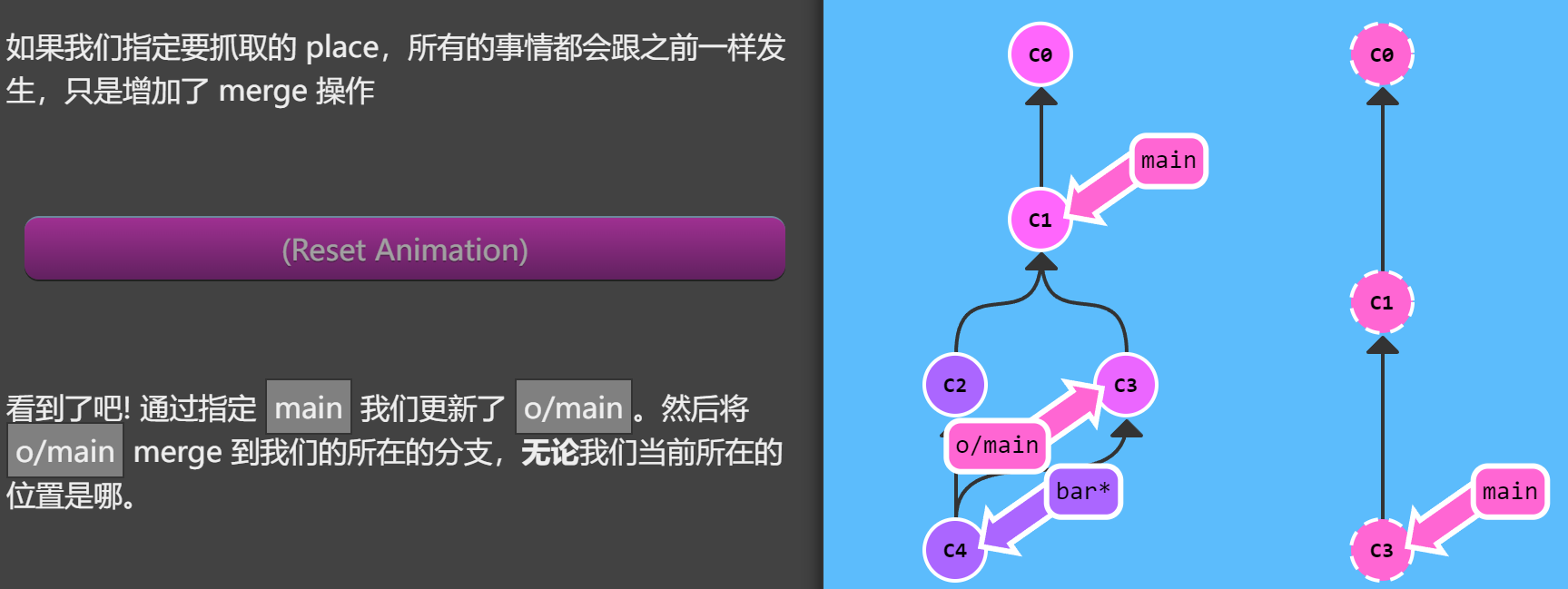
如果我们指定要抓取的 place,所有的事情都会跟之前一样发生,只是增加了 merge 操作
1 | git pull origin main |
pull 也可以用 source:destination 吗? 当然喽, 看看吧:
1 | git pull origin main:foo |
哇, 这个命令做的事情真多。它先在本地创建了一个叫 foo 的分支,从远程仓库中的 main 分支中下载提交记录,并合并到 foo,然后再 merge 到我们的当前所在的分支 bar 上。操作够多的吧?!