Linux 性能调优1——CPU
前言:最近的工作中涉及到了太多Linux相关调试方法与原理性的问题,但是前期工作太忙一直没来得及好好学习,仔细钻研,最近项目算是告一段落,因此希望能借此机会精进一下技术并好好总结一些方法与原理
CPU相关性能调试基本原理
在Linux系统中,影响性能的指标主要为CPU、内存、IO、网络,每个模块都有其特定的调试方式和工具。与CPU相关的主要调试方向为进程和线程、软硬件的中断、和上下文的切换情况。
进程和线程
进程是资源拥有的基本单位,线程是调度的基本单位。进程与线程在内核中使用的结构体都为task_struct,二者间区别主要是进程的pid=tgid,线程的pid!=tgid。
进程状态:
- TASK_RUNNING 并不是说进程正在运行,而是表示进程在时刻准备运行的状态
- TASK_INTERRUPTIBLE 因等待事件(比如IO事件)而进入睡眠
- TASK_UNINTERRUPTIBLE 因等待事件(比如IO事件)而进入睡眠,不可以被信号唤醒
调度
调度策略
普通调度策略
SCHED_NORMAL:普通进程
SCHED_BATCH:后台进程
SCHED_IDLE:空闲进程
实时调度策略
SCHED_FIFO:高优先级的进程可以抢占低优先级的进程,而相同优先级的进程,先到先得
SCHED_RR:高优先级的进程可以抢占低优先级的进程,而相同优先级的进程,轮换着来
SCHED_DEADLIN7E
调度优先级
实时进程:0 ~ 99
普通进程:100 ~ 139
调度器类
Fair
常用的策略为:SCHED_NORMAL、SCHED_BATCH、SCHED_IDLE
完全公平算法 – CFS
CFS对应的调度策略:SCHED_NORMAL、SCHED_BATCH、SCHED_IDLE。 CFS 会为每一个进程安排一个虚拟运行时间 vruntime。如果一个进程在运行,随着时间的增加,进程的 vruntime 将不断增大。没有得到执行的进程 vruntime 不变。 显然,那些 vruntime 少的,原来受到了不公平的对待,需要给它补上,所以会优先运行这样的进程。 你可能会说,不还有优先级呢?如何给优先级高的进程多分时间呢?按比例!
Real_Time
常用的策略为:SCHEDFIFO 和 SCHEDRR
中断
硬件中断的处理目前都算比较快,所以目前的调试都不会特别关注硬件中断的过程,主要关注的是软件中断的过程,因为会占用比较大量的时间
上下文切换
CPU上下文
包括CPU寄存器和程序计数器
CPU寄存器:是 CPU 内置的容量小、但速度极快的内存
程序计数器:是用来存储 CPU 正在执行的指令位置、或者即将执行的下一条指令位置(PC指针)
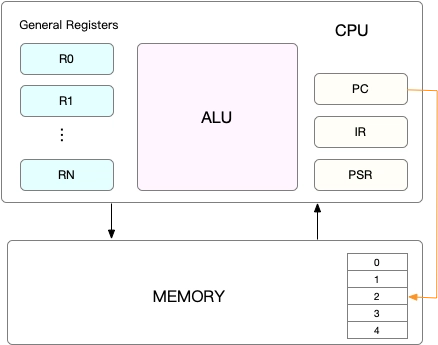
- CPU上下文切换:是先把前一个任务的 CPU 上下文(也就是CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务
- 这些这些保存下来的上下文,会存储在系统内核中,并在任务重新调度执行时再次加载进来
根据任务的不同,CPU的上下文切换分为进程上下文切换、线程上下文切换和中断下文切换
进程上下文切换
Linux 按照特权等级,把进程的运行空间分为内核空间和用户空间,分别对应着下图中, CPU 特权等级的 Ring 0 和 Ring 3。
- 内核空间(Ring 0)具有最高权限,可以直接访问所有资源;
- 用户空间(Ring 3)只能访问受限资源,不能直接访问内存等硬件设备,必须通过系统调用陷入到内核中,才能访问这些特权资源。
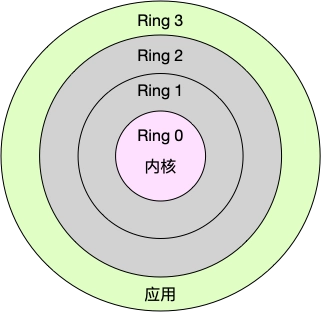
从进程用户态到内核态的转变,需要通过系统调用来完成,系统调用的过程中会发生两次CPU上下文切换。CPU里原来用户态指令的执行位置需要先保存起来,然后更新为内核态执行的指令位置,最后跳转到内核态运行内核任务。在系统调用结束后,CPU 寄存器需要恢复原来保存的用户态,然后再切换到用户空间,继续运行进程。
注意:
-
系统调用的过程中,不会涉及到虚拟内存等进程态的资源,不会切换进程,系统调用过程和进程上下文切换不一样,整个过程都是同一个进程
-
系统调用称为特权模式切换,不是上下文切换
进程上下文切换和系统调用的区别:
进程的上下文切换就比系统调用时多了一步:在保存当前进程的内核状态和 CPU 寄存器之前,需要先把该进程的虚拟内存、栈等保存下来;而加载了下一进程的内核态后,还需要刷新进程的虚拟内存和用户栈

保存上下文和恢复上下文的过程需要内核在CPU上运行才能完成(上下文切换过程是CPU密集型),每次上下文切换都需要几十纳秒到数微秒的 CPU 时间。
在进程上下文切换次数较多的情况下,很容易导致 CPU 将大量时间耗费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,进而大大缩短了真正运行进程的时间,从而导致系统平均负载升高。
Linux 通过 TLB(Translation Lookaside Buffer)来管理虚拟内存到物理内存的映射关系。当虚拟内存更新后,TLB 也需要刷新,内存的访问也会随之变慢。特别是在多处理器系统上,缓存是被多个处理器共享的,刷新缓存不仅会影响当前处理器的进程,还会影响共享缓存的其他处理器的进程。
Linux 为每个 CPU 都维护了一个就绪队列,将活跃进程(即正在运行和正在等待 CPU 的进程)按照优先级和等待 CPU 的时间排序,然后选择最需要 CPU 的进程,也就是优先级最高和等待 CPU 时间最长的进程来运行。
进程被CPU重新调度的时机:
- 进程执行完终止了,它之前使用的 CPU 会释放出来,这个时候再从就绪队列里,拿一个新的进程过来运行
- 为了保证所有进程可以得到公平调度,CPU 时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。这样,当某个进程的时间片耗尽了,就会被系统挂起,切换到其它正在等待 CPU 的进程运行
- 进程在系统资源不足(比如内存不足)时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行
- 进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,自然也会重新调度
- 有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行
- 发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序
线程上下文切换
线程和进程的区别:线程是调度的基本单位,而进程则是资源拥有的基本单位。
所谓内核中的任务调度,实际上的调度对象是线程;而进程只是给线程提供了虚拟内存、全局变量等资源。
- 当进程只有一个线程时,可以认为进程就等于线程
- 当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源。这些资源在上下文切换时是不需要修改的
- 另外,线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时也是需要保存的
因此,线程的上下文切换分为两种情况:
- 前后两个线程属于不同进程。此时,因为资源不共享,所以切换过程就跟进程上下文切换是一样
- 前后两个线程属于同一个进程。此时,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据
注意:同进程的线程切换要比进程间的切换消耗更少的资源,更加轻量级
中断上下文切换
为了响应硬件事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。
中断上下文切换不会涉及到进程的用户态,它其实只包括内核态中断服务程序执行所必需的状态,包括CPU 寄存器、内核堆栈、硬件中断参数等
对同一个 CPU 来说,中断处理比进程拥有更高的优先级,所以中断上下文切换并不会与进程上下文切换同时发生
大部分中断处理程序都短小精悍,以便尽可能快的执行结束。
中断上下文切换也需要消耗 CPU,切换次数过多也会耗费大量的 CPU,甚至严重降低系统的整体性能
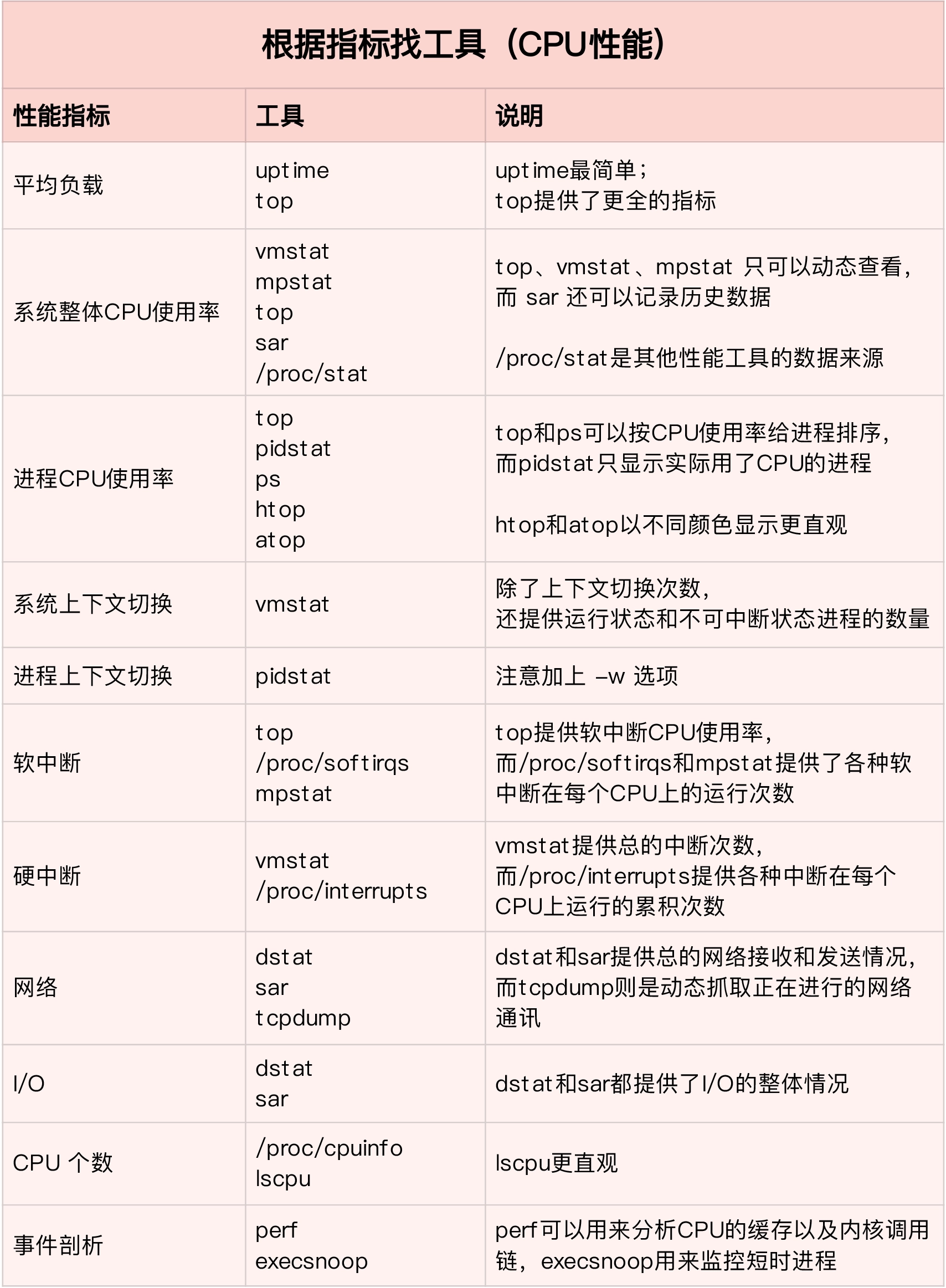
性能指标1——CPU使用率
CPU的使用率,就是一段时间内有进程在CPU上运行的时间占总时间的比例,包含:用户CPU、系统CPU、iowait、硬件中断、软件中断等。
相关工具
top
top工具的输出一般像下面这样:
1 | top |
top的输出:
us: un-niced用户进程使用的cpu时间;
sy:系统的内核进程
ni: 被调整过nice值的进程占用的CPU使用率;
wa:就是IO-wait;
hi:hardware Interrupt
si:software interrupt
mpstat
mpstat的输出和top不一样:
%usr: 用户进程使用的cpu时间(包含un-niced和niced);
%nice: niced用户进程使用的cpu时间
显示所有CPU的指标,每秒一次
1 | mpstat -P ALL 1 |
pidstat
pidstat输出:
%user表示用户进程使用的cpu时间(包含un-niced和niced);
%wait表示任务等待运行时所占用的CPU百分比。
显示所有进程的CPU指标,每秒一次:
1 | pidstat -u 1 |
gdb
perf
实时显示CPU时钟占用最多的函数或指令
平均负载最理想的指标值是等于CPU的个数。
调试技巧
- us cpu 占用高,说明用户态进程占用了较多cpu,着重排查应用程序本身的代码逻辑问题;
- sy cpu占用高,说明内核态代码占用了较多的 CPU,所以应该着重排查内核线程或者系统调用的性能问题;
- wa cpu占用高,说明等待 I/O 完成所花的时间比较长,所以应该着重排查linux系统是不是存在IO相关的性能瓶颈;
- hi和si占用高,说明软中断或硬中断的处理程序占用了较多的 CPU,所以应该着重排查内核中的中断服务程序,一般是网络;
- 系统整体cpu使用较高,而实际的单个进程的cpu使用都不高,要考虑短时进程是否被频繁创建和销毁;
性能指标2——平均负载
平均负载是指单位时间内,系统处于可运行状态(Running)和不可中断等待状态(uninterruptible)的平均进程数
平均负载为3,意味着:
1、在只有3个CPU 的系统上,意味着所有的CPU都刚好被进程完全占用;
2、在6个CPU的系统上,意味着CPU有50% 的空闲;
3、在只有1个CPU 的系统中,则意味着2/3的进程竞争不到CPU;
平均负载是一个综合性的指标,需要通过整体变化趋势来看系统是否有压力
相关工具
uptime
top
dstat -y
调优技巧
- 平均负载高可能是cpu密集型进程导致的;
- 平均负载高并不一定代表 CPU 使用率高,还有可能是等待I/O的进程变多了;
- 平均负载高的时候,需要辅助其他的工具来做进一步的分析;
性能指标3——上下文切换
如果系统的上下文切换次数比较稳定,那么理想数据是1万以内
相关工具
vmstat
cs列:系统每秒上下文切换的次数。
r列:处于可运行态的进程数量
b列:处于不可中断睡眠状态的进程数量
1 | # 每隔5s输出一组数据 |
参数:
cs:context switch,每秒上下文切换的次数in:interrupt ,每秒中断的次数r:就绪队列的长度(正在运行和等待CPU的进程数)b:blocked,处于不可中断睡眠状态的进程数
pidstat
显示进程的每秒自愿和非自愿上下文切换次数:
1 | pidstat -w |
命令:pidstat
1 | $ [root@VM_194_74_centos ~]# pidstat -w 5 |
参数:
- cswch:每秒自愿上下文切换的次数(voluntary context switch)
- nvcswch:每秒非自愿上下文切换的次数(non voluntary context switch)
自愿上下文切换:进程无法获取所需资源导致的上下文切换,比如I/O,内存等系统资源不足时发生的上下文切换
非自愿上下文切换:进程因时间片已到等原因,被系统强制调度发生的上下文切换,比如多个进程竞争CPU是发生的上下文切换
/proc/interrupts
/proc/softirqs
调优技巧
如果进程的自愿上下文切换多了,表示进程在等待资源;
如果进程的非自愿上下文切换多了,说明进程在被强制调度(被实时性更高的进程抢占);
如果中断次数多了,说明中断处理程序在占用大量的cpu;
如果软中断次数多了,说明下半部处理程序在占用大量的cpu,一般是网络;
调优工具
top
数据及指标
us: 代表用户态cpu时间,不包含被调 整过nice值的进程所占的cpu时间;
ni: 代表被调整过nice值的进程占用的cpu时间;
sy: 代表内核态cpu时间
id: 空闲时间,注意,它不包括等待 I/O 的时间(iowait)
wa: 代表等待I/O的cpu时间
hi: 代表硬件中断占据的cpu时间
si: 代表软件中断占据的cpu时间
[例子]
1、stress命令起1个进程:
stress -c 1
2、top查看
3、renice
renice -n 5 -p 26205
4、top查看可见进程26205的cpu用量由原来的统计到us变成了统计到ni上
可添加的参数
-p {pid}:只显示某个进程的状态
以下内容中【交互】表示使用top命令实时显示数据时输入对应的选项会将实时显示的数据进行对应的变化
【交互】h: 显示帮助
【交互】c: 切换显示完整的命令行
【交互】M:根据常驻内存(RES)用量进行排序
【交互】P: 根据CPU使用百分比大小进行排序
【交互】S:切换到累加模式
【交互】T:根据时间或者累计时间进行排序(TIME+列)
【交互】s:改变两次刷新的延迟时间,默认是3s
【交互】r:修改某个进程的nice值(对应top的NI列)
ps
显示所有进程:
1 | ps -ef |
显示所有线程:
1 | ps -eLf或ps -eTf |
ps统计的是进程的整个生命周期,top是实时的消耗,默认是三秒内
ps的可选项:
-e:选择所有进程
-o:用于设定输出格式
例如: -o stat,ppid,pid,cmd 表示只输出进程的stat(状态信息)、ppid(父进程pid)、pid(当前进程的pid),cmd(即进程的可执行文件)
-L Show threads, possibly with LWP and NLWP columns
-T Show threads, possibly with SPID column
-m Show threads after processes.
-f 全格式输出
-a 选择所有进程,除了session leader(见getsid(2))和与terminal不相关的进程。
-A, 选择所有进程(同-e)
mpstat
用法:
mpstat -P ALL 1
sar
用法
前提条件: 1. sudo vi /etc/default/sysstat //把false修改为true 2. sudo service sysstat restart //重启sysstat服务
pidstat
%usr: 进程在用户态执行的cpu时间 %system: 进程在内核态执行的cpu时间 %wait: 进程等待运行时所花费的CPU时间
用法
每隔1秒输出一组进程的cpu数据: $ pidstat -u 1
-p {pid} 指定查看某个进程的信息
-U {usrname} 显示属于这个用户的进程
-r:内存-d: IO
kB_rd/s:该进程每秒从磁盘读取的数据大小
kB_wr/s:该进程每秒写入磁盘的数据大小
kB_ccwr/s:每秒取消的写请求数据大小iodelay:块 I/O 延迟,包括等待同步块 I/O 和换入块 I/O 结束的时间,单位是时钟周期。
-u: cpu(默认)
-R: 进程的realtime priority and scheduling policy
-w:进程的上下文切换信息
cswch/s:每秒自愿进行上下文切换的次数
1、所谓自愿上下文切换,是指进程无法获取所需资源,导致的上下文切换。比如说, I/O、内存等系统资源不足时,就会发生自愿上下文切换; 2、而非自愿上下文切换,则是指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。比如说,大量进程都在争抢 CPU 时,就容易发生非自愿上下文切换。
nvcswch/s:表示每秒非自愿上下文切换的次数-v:进程相关的线程数和文件描述符数量
-s:进程stack所用内存信息
perf
用法
perf list:
列出所有能够触发perf采样点的事件,类似/sys/kernel/debug/tracing/available_events的输出
实测发现,perf 支持的事件要比ftrace多一倍左右。
perf probe:
定义新的动态tracepoint
–add:添加一个probe event
例如:perf probe --add do_sys_open
–del:删除probe event
例如:perf probe --del probe:do_sys_open
例子:perf record -e probe:do_sys_open -aR sleep 10
perf trace:
类似strace,不过性能更佳,例如:perf trace ls
perf stat:
运行命令并收集性能统计信息
perf top:
可以实时查看当前系统进程函数占用率情况
perf record:
运行命令并保存profile到perf.data
-p {pid} 记录进程的events
-a:从所有cpu上进行采集
-e {event}:指定PMU(处理器监控单元) event ,默认是cycles:ppp(CPU周期数)
-g:启用调用图(堆栈链/回溯)记录
-F {freq}:采样频率例如:
perf record -p 12069 -a -g -F 99 – sleep 10
perf record -p 12069 -a -g -F 999 – sleep 10
perf record -g -e cpu-clock ./perftest
perf report:
从perf.data读取并显示profile
–no-children:不统计Children开销
Self:Self 记录的是最后一列的符号(可以理解为函数)本身的采样数占总采样数的百分比
目的:找到最底层的热点函数Children:记录的是这个符号调用的其他符号(理解为子函数,包括直接调用和间接调用)的采样数之和占总采样数的百分比
目的:找到较高层的热点函数
perf script:
从perf.data读取并显示详细的采样数据
perf kmem:
跟踪/测量内核内存属性
record:记录kmem events
–slab:记录slab申请器的events
–page:记录page 申请器的events
stat:报告内核内存统计信息
–slab:统计slab申请器的events
–page:统计page 申请器的events
perf mem:
分析内存访问
perf lock:
分析锁性能
perf kvm:
针对kvm虚拟化分析
perf sched:
分析内核调度器性能
record:采集和记录scheduling events
例如(全局):perf sched record – sleep 10
例如(进程):perf sched record -p 752 – sleep 10script:报告采集到的事件
latency:报告每个任务的调度延迟和进程的其他调度属性
timehist:提供调度事件的分析报告
火焰图
火焰图的横轴和纵轴的含义: - 横轴表示采样数和采样比例。一个函数占用的横轴越宽,就代表它的执行时间越长。同一层的多个函数,则是按照字母来排序。 - 纵轴表示调用栈,由下往上根据调用关系逐个展开。换句话说,上下相邻的两个函数中,下面的函数,是上面函数的父函数。这样,调用栈越深,纵轴就越高。 火焰图不包含任何时间的因素,所以并不能看出横向各个函数的执行次序。
场景
寻找热点函数,定位性能瓶颈
具体实现是对事件进行采样,然后再根据采样数,评估各个函数的调用频率,
perf 可以用来分析 CPU cache、CPU 迁移、分支预测、指令周期等各种硬件事件
perf 也可以只对感兴趣的事件进行动态追踪
实践过程
寻找热点函数,定位性能瓶颈
自定义追踪函数
1、添加 do_sys_open 探针 $ perf probe --add do_sys_open 2、采样和追踪 $ perf record -e probe:do_sys_open -aR sleep 1 3、查看采样结果 $ perf script 4、删除探针 $ perf probe --del probe:do_sys_open
pstree
用法
经典用法: $ pstree -p 5638 显示5638这个进程的进程树(包含线程) $ pstree -T -p 5638 显示5638这个进程的进程树(不包含线程)
-a 显示命令行参数 If the command line of a process is swapped out,则该进程将显示在括号中,例如类似这样: -{kubeensaas}(8)
-c 禁止压缩子树(压缩后不显示子树信息)
-n 通过pid而不是name对相同祖先的进程排序
-g 显示PGIDs
-p 显示某个进程的进程树(包含线程)
-T 隐藏线程、只显示进程
taskset
用法
-pc 0x3 {pid}:绑定cpu0和cpu1到进程
-pc {pid}:查看进程绑定的cpu(输出为3,也就是011,表示第0,1个cpu)
cpulimit
用法
-p {pid} -l {percent}:进程允许的cpu用量为percent%
-k:如果进程cpu超量,直接杀掉进程而不是限制cpu使用(默认);
-m:输出统计信息;
pstack
$ pstack 11613 11613: ./jin pstack: Input/output error failed to read target. 【解决】 参考此处: https://blog.csdn.net/u010164190/article/details/111059283
用法
pstack{pid}对指定PID的进程输出函数调用栈
场景
应用并未崩溃,如何查看stack trace信息?
strace
用法
-p {pid}
-f 跟踪子进程
-t 在输出中的每一行前加上时间信息
-T 显示每一个系统调用所耗的时间
-c 统计每一个系统调用的调用次数、错误次数、执行时间和执行时间占比
场景
正在运行的程序实际读取的是哪个配置文件?
程序好像hang住了,具体是什么情况,为什么hang住?hang在了哪里?
进程运行很慢,但是没有源代码,想看看时间都花在了哪里?
容器环境下,如何对应用程序的网络行为进行调试和追踪?
stap
用法
stap --all-modules dropwatch.stp
/proc
用法
通过子进程的Pid得到父进程的Pid:cat /proc/{pid}/status | grep PPid
调试方法
用户cpu使用率较高 checklist
分析过程
- 通过top命令查看系统整体的cpu使用率和平均负载
- pidstat -u 1| more 查看进程的cpu使用率,找到可疑进程
- pstree -p {pid}查看进程的进程结构(继承关系)
- strace -f -p {pid} 追踪进程的系统调用情况,是否存在频繁的系统调用?
- pstack {pid}找到代码瓶颈点
软中断cpu使用率较高,Checklist
分析过程
- 通过top命令查看系统整体的cpu使用率和平均负载
- watch -d cat /proc/softirqs 找到瓶颈所在的软件中断
- perf record -g 采集内核事件
- perf report分析事件,找到瓶颈所在的内核函数代码
cpu使用率较高,Checklist
分析过程
- 通过top命令查看系统整体的cpu使用率和平均负载
- pidstat -u 1| more
查看进程的cpu使用率,找到可疑进程 - iostat查看系统整体的I/O情况
- iotop查看进程的I/O压力情况
- strace -f -p {pid} 追踪进程的系统调用情况,是否存在频繁的系统调用?
案例分析
sysbench模拟多线程调度切换
准备
一台Linux机器,打开三个终端
正式实战
- 第一个终端:运行
sysbench
1 | # 以10个线程运行5分钟的基准测试,模拟多线程切换的问题 |
- 第二个终端:运行
vmstat
1 | # 每隔1秒输出1组数据(需要Ctrl+C才结束) |
指标观察:
-
cs列:上升到39万
-
r列:就绪队列长度上升到8
-
in列:终端次数上升到1万
-
us(user)和sy(system)列:使用率加起来100%,sy为84%,主要被内核占用
- 查看进程情况
1 |
|
分析:CPU 使用率的升高果然是 sysbench 导致的,它的 CPU 使用率已经达到了 100%。但上下文切换则是来自其他进程,包括非自愿上下文切换频率最高的 pidstat ,以及自愿上下文切换频率最高的内核线程 kworker 和 sshd
注意:pidstat 输出的上下文切换次数,加起来也就几百,比 vmstat 的 139 万明显小了太多?
- 查看线程的情况
可以看到,sysbench 进程(也就是主线程)的上下文切换次数看起来并不多,但它的子线程的上下文切换次数却有很多。上下文切换罪魁祸首,还是过多的 sysbench 线程
1 | # 每隔1秒输出一组数据(需要 Ctrl+C 才结束) |
- 查看中断升高的原因
根据前文的分析,中断次数也升高到了1万左右,从/proc/interrupts只读文件查看中断情况
1 | # -d 参数表示高亮显示变化的区域 |
观察发现,变化速度最快的是重调度中断(RES),它代表唤醒空闲状态的 CPU 来调度新的任务运行,这是在多处理器系统(SMP)中,调度器用来分散任务到不同 CPU 的机制,通常也被称为处理器间中断(Inter-Processor Interrupts,IPI)
分析:过多任务导致了重调度中断的升高,和前面分析结果一致
每秒上下文切换多少次正常?
上下文切换次数取决于系统本身的CPU性能。如果系统的上下文切换次数比较稳定,那么从数百到一万以内,都应该算是正常的。但当上下文切换次数超过一万次,或者切换次数出现数量级的增长时,就很可能已经出现了性能问题,这时根据具体上下文切换的类型具体分析:
- 自愿上下文切换变多了,说明进程都在等待资源,有可能发生了 I/O 等其他问题
- 非自愿上下文切换变多了,说明进程都在被强制调度,也就是都在争抢 CPU,说明 CPU 的确成了瓶颈
- 中断次数变多了,说明 CPU 被中断处理程序占用,还需要通过查看 /proc/interrupts 文件来分析具体的中断类型
系统出现大量不可中断进程和僵尸进程怎么办?
进程状态
-
R:表示正在就绪队列中的进程,正在运行或者正在等待运行
-
D:Disk Sleep,不可中断状态睡眠(Uninterruptible Sleep),一般是进程和硬件交互,并且交互过程不允许其他进程或中断打断
-
Z :Zombie 的缩写,它表示僵尸进程,也就是进程实际上已经结束了,但是父进程还没有回收它的资源(比如进程的描述符、PID 等)
-
S :Interruptible Sleep 的缩写,也就是可中断状态睡眠,表示进程因为等待某个事件而被系统挂起。当进程等待的事件发生时,它会被唤醒并进入 R 状态
-
I: Idle 的缩写,也就是空闲状态,用在不可中断睡眠的内核线程上。前面说了,硬件交互导致的不可中断进程用 D 表示,但对某些内核线程来说,它们有可能实际上并没有任何负载,用 Idle 正是为了区分这种情况。要注意,D 状态的进程会导致平均负载升高, I 状态的进程却不会
-
T:Stopped或者Traced,表示进程处于暂停或者跟踪状态(SIGSTOP信号会让进程变为暂停状态,再发送SIGCONT信号,进程又会恢复运行)
-
X:Dead,表示进程已经消亡,top或者ps看不到
不可中断状态,是为了保证进程数据与硬件状态一致,正常情况下,不可中断状态在很短时间内就会结束。短时的不可中断状态进程,我们一般可以忽略。
但如果系统或硬件发生了故障,进程可能会在不可中断状态保持很久,甚至导致系统中出现大量不可中断进程。需要注意下,系统是不是出现了 I/O 等性能问题。
注意:ps查看进程状态时,会有Ss+,D+等情况,其中s表示进程是会话的领导进程,+表示前台进程组
案例分析
指标分析
- 运行案例的docker
1 | docker run --privileged --name=app -itd feisky/app:iowait |
- top查看指标
1 | # 按下数字 1 切换到所有 CPU 的使用情况,观察一会儿按 Ctrl+C 结束 |
- 分析
- 第一行的平均负载( Load Average),过去 1 分钟、5 分钟和 15 分钟内的平均负载在依次减小,说明平均负载正在升高;而 1 分钟内的平均负载已经达到系统的 CPU 个数,说明系统很可能已经有了性能瓶颈。
- 第二行的 Tasks,有 1 个正在运行的进程,但僵尸进程比较多,而且还在不停增加,说明有子进程在退出时没被清理。
- CPU 的使用率情况,用户 CPU 和系统 CPU 都不高,但 iowait 分别是 60.5% 和 94.6%,好像有点儿不正常。
- 最后再看每个进程的情况, CPU 使用率最高的进程只有 0.3%,看起来并不高;但有两个进程处于 D 状态,它们可能在等待 I/O,但光凭这里并不能确定是它们导致了 iowait 升高。
- 结论
- 第一点,iowait 太高了,导致系统的平均负载升高,甚至达到了系统 CPU 的个数
- 第二点,僵尸进程在不断增多,说明有程序没能正确清理子进程的资源。
iowait分析
- dstat查看系统I/O情况
1 | # 间隔1秒输出10组数据 |
可以看到,每当 iowait 升高(wai)时,磁盘的读请求(read)都会很大。这说明 iowait 的升高跟磁盘的读请求有关,很可能就是磁盘读导致的
- pidstat分析D状态的进程
1 | # -d 展示 I/O 统计数据,-p 指定进程号,间隔 1 秒输出 3 组数据 |
- kB_rd 表示每秒读的 KB 数
- kB_wr 表示每秒写的 KB 数
- iodelay 表示 I/O 的延迟(单位是时钟周期)。
- 它们都是 0,那就表示此时没有任何的读写,说明问题不是 4344 进程导致的。
- pidstat查看所有进程情况
1 | # 间隔 1 秒输出多组数据 (这里是 20 组) |
观察一会儿可以发现,的确是 app 进程在进行磁盘读,并且每秒读的数据有 32 MB,看来就是 app 的问题。不过,app 进程到底在执行啥 I/O 操作呢?进程想要访问磁盘,就必须使用系统调用,所以接下来,重点就是找出 app 进程的系统调用
- strace跟踪进程
1 | $ strace -p 6082 |
- 检查一下进程的状态,已经变成僵尸进程
1 | $ ps aux | grep 6082 |
- 动态追踪
1 | $ perf record -g |
如下图,swapper是内核的调度进程,可忽略
可以发现, app 的确在通过系统调用 sys_read() 读取数据。并且从 new_sync_read 和 blkdev_direct_IO 能看出,进程正在对磁盘进行直接读,也就是绕过了系统缓存,每个读请求都会从磁盘直接读,这就可以解释我们观察到的 iowait 升高了
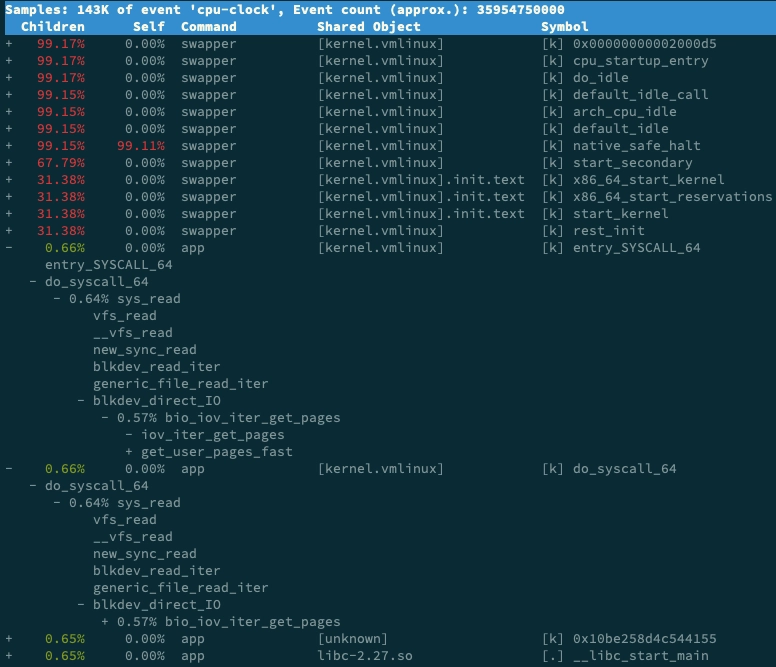
- 打开app.py文件,可以看到使用了 O_DIRECT 选项打开磁盘
1 | open(disk, O_RDONLY|O_DIRECT|O_LARGEFILE, 0755) |
直接读写磁盘,对 I/O 敏感型应用(比如数据库系统)是很友好的,因为你可以在应用中,直接控制磁盘的读写。但在大部分情况下,我们最好还是通过系统缓存来优化磁盘 I/O
- 修复代码
修复后的文件名app-fix1.py,运行docker如下
1 | # 首先删除原来的应用 |
top检查
1 | $ top |
僵尸进程分析
僵尸进程是因为父进程没有回收子进程的资源而出现的,那么,就需要找出父进程,然后在父进程里解决。
- pstree
1 | # -a 表示输出每个程序完整的命令(包含路径,参数或是常驻服务的标示) |
- 查看app-fix1.py代码
1 | int status = 0; |
可以发现,文件错误地把 wait() 放到了 for 死循环的外面,也就是说,wait() 函数实际上并没被调用到,我们把它挪到 for 循环的里面就可以了。
修改后的文件我放到了 app-fix2.c ,运行对应的docker
1 | # 先停止产生僵尸进程的 app |
-
top查看
僵尸进程(Z 状态)没有了, iowait 也是 0,问题解决
1 |
|
怎么理解CPU软中断
中断是一种异步的事件处理机制,可以提高系统的并发处理能力
为了减少对正常进程运行调度的影响,中断处理程序应该尽快完成
软中断
中断过程分为上半部和下半部:
- 上半部:用来快速处理中断,它在中断禁止模式下运行,主要处理和硬件紧密相关或者时间敏感的工作
- 下半部:用来延迟处理上半部未完成的工作,通常以内核线程的形式运行
网卡接收数据包的例子:网卡接收到数据包后,会通过硬件中断的方式,通知内核有新的数据到了。对上半部来说,既然是快速处理,其实就是要把网卡的数据读到内存中,然后更新硬件寄存器的状态(表示数据已经读好了),最后再发送一个软中断信号,通知下半部做进一步的处理。而下半部被软中断信号唤醒后,需要从内存中找到网络数据,再按照网络协议栈,对数据进行逐层解析和处理,直到把它送给应用程序。
可以理解为:上半部快速执行,下半部延迟执行
查看软中断和内核线程
- 查看/proc文件系统
- /proc/softirqs,提供了软中断的运行情况
- /proc/interrupts,提供了硬中断的运行情况
1 | # 可以看到各类软中断在不同CPU上累积的运行次数 |
注意:
- 软中断的类型:第一列的内容,对应软中断的类型,比如NET_TX代表网络接收中断,NET_RX代表网络发送中断,SCHE代表调度,TIMER代表定时器等等
- 每种软中断在不同CPU上的运行情况:同一行的内容,正常情况下,同一种中断在不同CPU上的累计次数应该差不多,比如NET_RX。 而TASKLET只在调用它的函数所在的CPU运行(存在的问题:由于只在一个 CPU 上运行导致的调度不均衡,或者因为不能在多个 CPU 上并行运行带来了性能限制)
- 软中断以内核线程方式运行,每个CPU都对应一个软中断内核线程(ksoftirqd/CPU编号)
1 | $ ps aux | grep softirq |
系统的软中断CPU使用率升高,该怎么办?
案例准备
工具介绍:
- sar 是一个系统活动报告工具,既可以实时查看系统的当前活动,又可以配置保存和报告历史统计数据。
- hping3 是一个可以构造 TCP/IP 协议数据包的工具,可以对系统进行安全审计、防火墙测试等。
- tcpdump 是一个常用的网络抓包工具,常用来分析各种网络问题
案例图示
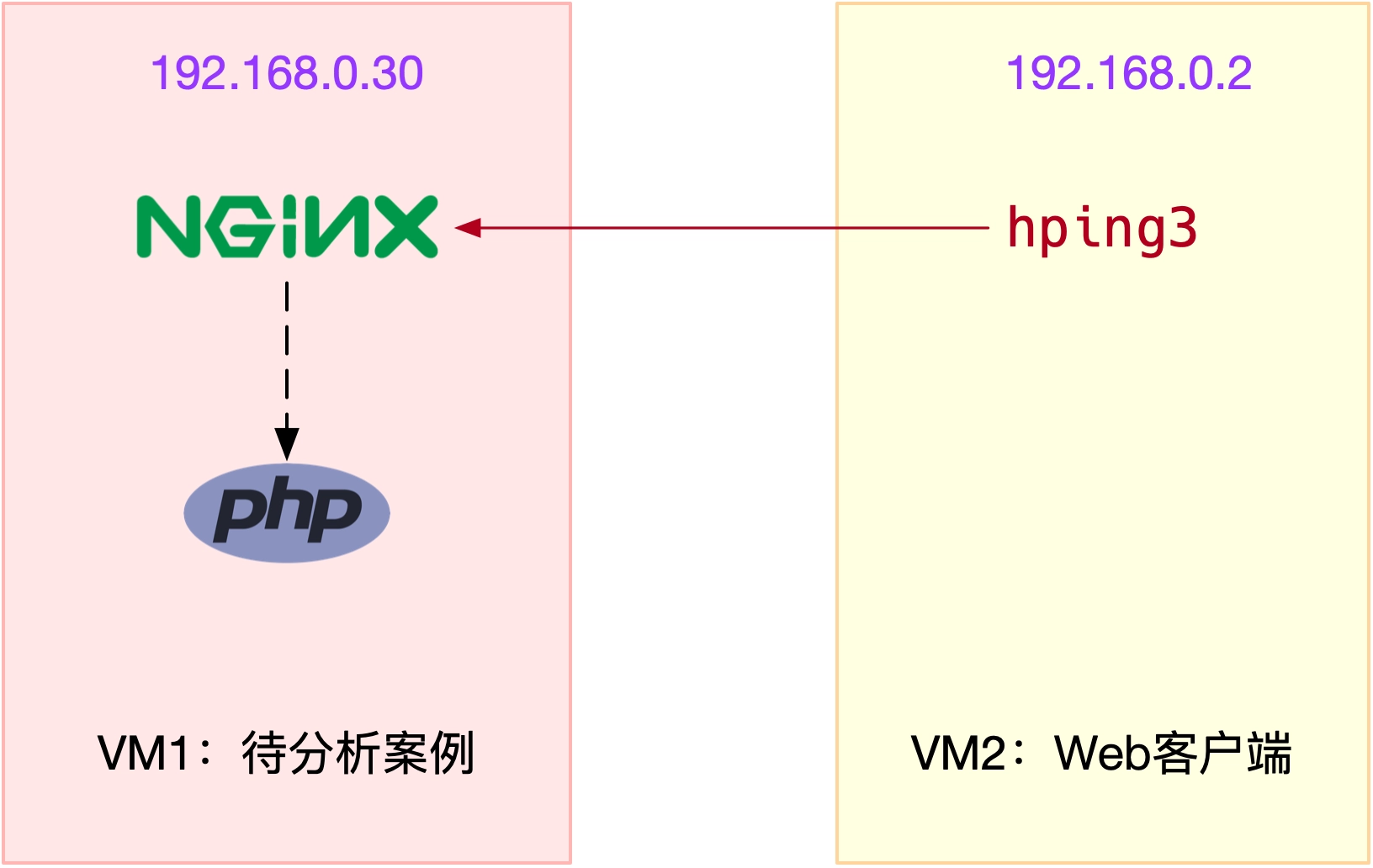
其中一台虚拟机运行 Nginx ,用来模拟待分析的 Web 服务器;而另一台当作 Web 服务器的客户端,用来给 Nginx 增加压力请求
操作和分析
运行Nginx应用
1 | # 运行Nginx服务并对外开放80端口 |
在另一个终端运行hping3模拟客户端的请求
1 | # -S参数表示设置TCP协议的SYN(同步序列号),-p表示目的端口为80 |
会发现简单的shell命令都变慢了,执行top查看系统整体情况
1 | # top运行后按数字1切换到显示所有CPU |
可以看到:
- 平均负载全是 0,就绪队列里面只有一个进程(1 running)。
- 每个 CPU 的使用率都挺低,最高的 CPU1 的使用率也只有 4.4%,并不算高。
- 再看进程列表,CPU 使用率最高的进程也只有 0.3%
- 两个 CPU 的使用率虽然分别只有 3.3% 和 4.4%,但都用在了软中断上;而从进程列表上也可以看到,CPU 使用率最高的也是软中断进程 ksoftirqd
查看软中断变化情况
1 | $ watch -d cat /proc/softirqs |
可以发现, TIMER(定时中断)、NET_RX(网络接收)、SCHED(内核调度)、RCU(RCU 锁)等这几个软中断都在不停变化,这些中断是保证 Linux 调度、时钟和临界区保护这些正常工作所必需,变化是正常的。而其中的NET_RX,也就是网络数据包接收软中断的变化速率最快
使用sar工具查看网络收发情况(可以观察网络收发吞吐量和PPS)
1 | # -n DEV 表示显示网络收发的报告,间隔1秒输出一组数据 |
可以发现:
- 对网卡 eth0 来说,每秒接收的网络帧数比较大,达到了 12607,而发送的网络帧数则比较小,只有 6304;每秒接收的千字节数只有 664 KB,而发送的千字节数更小,只有 358 KB。
- docker0 和 veth9f6bbcd 的数据跟 eth0 基本一致,只是发送和接收相反,发送的数据较大而接收的数据较小。这是 Linux 内部网桥转发导致的,暂且不用深究,只要知道这是系统把 eth0 收到的包转发给 Nginx 服务即可
- 重点来看 eth0 :接收的 PPS 比较大,达到 12607,而接收的 BPS 却很小,只有 664 KB。直观来看网络帧应该都是比较小的,664*1024/12607 = 54 字节,说明平均每个网络帧只有 54 字节,这显然是很小的网络帧,也就是所谓的小包问题
tcpdump抓取eth0上的包,指定TCP协议和80端口
1 | # -i eth0 只抓取eth0网卡,-n不解析协议名和主机名 |
从 tcpdump 的输出中,你可以发现:
- 192.168.0.2.18238 > 192.168.0.30.80 ,表示网络帧从 192.168.0.2 的 18238 端口发送到 192.168.0.30 的 80 端口,也就是从运行 hping3 机器的 18238 端口发送网络帧,目的为 Nginx 所在机器的 80 端口。
- Flags [S] 则表示这是一个 SYN 包
最后,可以确定这是从192.168.0.2.18238来的SYN FLOOF攻击
SYN FLOOD 问题最简单的解决方法:从交换机或者硬件防火墙中封掉来源 IP,这样 SYN FLOOD 网络帧就不会发送到服务器中(后面的网络篇再进一步深究)
套路篇:如何迅速分析出CPU的瓶颈在哪里?
CPU性能指标
性能指标总览
CPU使用率
CPU 使用率描述了非空闲时间占总 CPU 时间的百分比,根据 CPU 上运行任务的不同,又被分为用户 CPU、系统 CPU、等待 I/O CPU、软中断和硬中断等。用户 CPU 使用率,包括用户态 CPU 使用率(user)和低优先级用户态
- CPU 使用率(nice),表示 CPU 在用户态运行的时间百分比。用户 CPU 使用率高,通常说明有应用程序比较繁忙。
- 系统 CPU 使用率,表示 CPU 在内核态运行的时间百分比(不包括中断)。系统 CPU 使用率高,说明内核比较繁忙。
- 等待 I/O 的 CPU 使用率,通常也称为 iowait,表示等待 I/O 的时间百分比。iowait 高,通常说明系统与硬件设备的 I/O 交互时间比较长。
- 软中断和硬中断的 CPU 使用率,分别表示内核调用软中断处理程序、硬中断处理程序的时间百分比。它们的使用率高,通常说明系统发生了大量的中断。
- 除了上面这些,还有在虚拟化环境中会用到的窃取 CPU 使用率(steal)和客户 CPU 使用率(guest),分别表示被其他虚拟机占用的 CPU 时间百分比,和运行客户虚拟机的 CPU 时间百分比。
平均负载
系统的平均活跃进程数。它反应了系统的整体负载情况,主要包括三个数值,分别指过去 1 分钟、过去 5 分钟和过去 15 分钟的平均负载。
理想情况下,平均负载等于逻辑 CPU 个数,这表示每个 CPU 都恰好被充分利用。如果平均负载大于逻辑 CPU 个数,就表示负载比较重了。
进程上下文切换
进程上下文切换分为:
- 自愿上下文切换
- 非自愿上下文切换
注意:过多的上下文切换,会将原本运行进程的 CPU 时间,消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上,缩短进程真正运行的时间,成为性能瓶颈
CPU缓存命中率
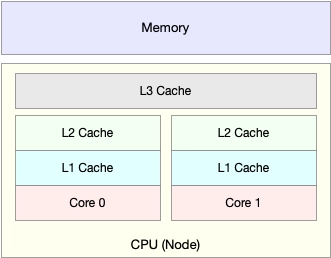
CPU 缓存的速度介于 CPU 和内存之间,缓存的是热点的内存数据。
如下图,根据不断增长的热点数据,这些缓存按照大小不同分为 L1、L2、L3 等三级缓存,其中 L1 和 L2 常用在单核中, L3 则用在多核中。从 L1 到 L3,三级缓存的大小依次增大,相应的,性能依次降低(当然比内存还是好得多)。而它们的命中率,衡量的是 CPU 缓存的复用情况,命中率越高,则表示性能越好。
CPU性能工具
- 平均负载案例:使用uptime查看平均负载,在平均负载升高时,使用mpstat和pidstat分别观察每个CPU和每个进程CPU的使用情况,找到导致平均负载升高的stress进程
- 上下文切换的案例:先使用vmstat,查看系统的上下文切换次数和中断次数;然后通过pidstat(-w参数)观察进程的自愿上下文切换和非自愿上下文切换;最后通过vmstat(-wt参数)查看线程的上下文切换情况,从而找到了线程上下文切换增多的原因是sysbench工具
- 进程CPU使用率升高的案例:先使用top找出系统和进程CPU的使用情况,发现了CPU使用率很高的进程php-fpm,再使用perf top找出热点函数sqrt();如果是Python应用,可以使用profiler工具pyflame对指定进程分析(pyflame -p pid --threads -s 检测时间 -r 取样间隔 -o <file.txt>),再通过flamegraph.pl将输出的txt文件转换为*.svg格式的火焰图(./flamegraph.pl prof.txt > prof.svg)
- 不可中断进程和僵尸进程的案例:
- 不可中断进程分析过程:先使用top查看,发现存在D状态(不可中断休眠进程)和Z状态(僵尸进程),并且iowait较高;使用dstat分析磁盘I/O,发现app进程有大量的磁盘读请求;使用pidstat(-d -p 参数)分析app进程的I/O操作,发现没有大量的I/O操作,再用pidstat -d分析系统的I/O情况,发现还是app进程在进行磁盘读;再使用strace跟踪D状态进程对应进程号的系统调用,发现没有权限;ps查看发现对应进程号的进程已经变成僵尸进程;之后,通过perf record -g和perf report生成报告,查看app进程的调用栈,发现CPU使用主要是在sys_read()函数,定位到是在对磁盘进行直接读(direct_IO);查看代码发现open()系统调用使用了O_DIRECT参数
- 僵尸进程分析:使用pstree命令找出僵尸进程的父进程是app进程,然后查看app.c文件,发现wait()使用位置不当导致不能回收子进程
- 软中断的案例:先使用top查看系统指标,发现系统CPU使用率很低,但是主要是在软中断si上,然后查看/proc/softirqs查看系统软中断变化情况,发现NET_RX变化率很快,再使用sar工具查看系统的网络收发情况,发现eth0网卡接收到了大量的小包;在通过抓包工具tcpdump,发现eth0接受到了大量的SYN包,最终确定了是SYN FLOOD攻击
性能指标找工具
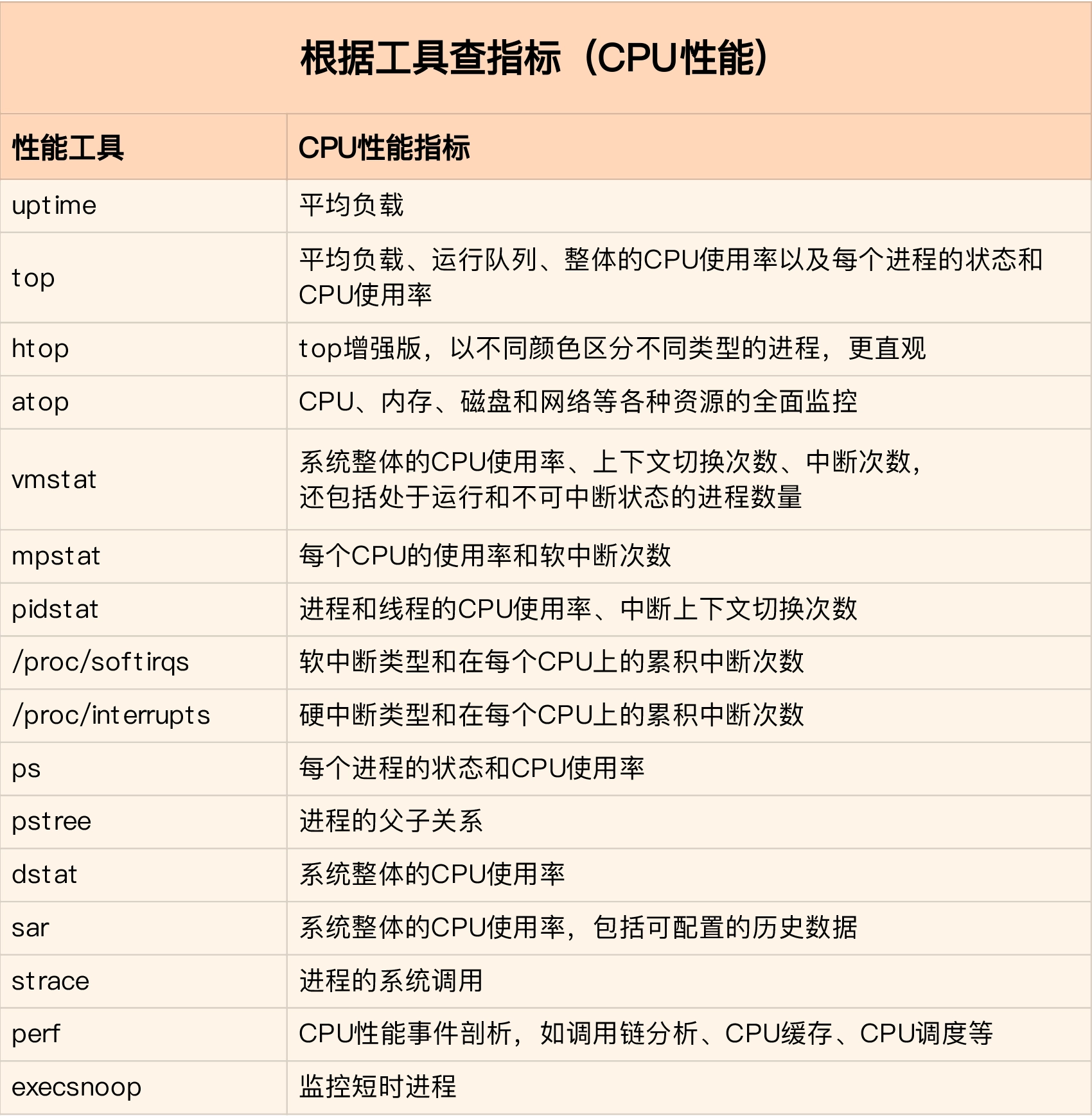
工具找指标
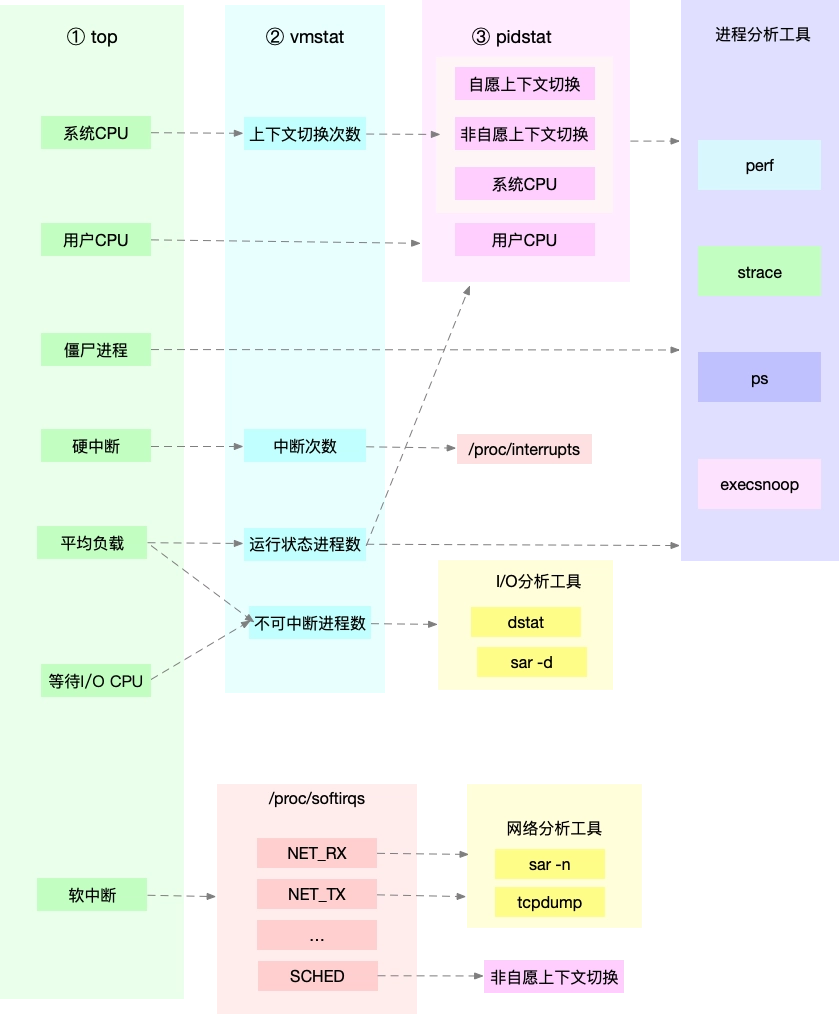
如何分析CPU的性能瓶颈
重点:弄清楚性能指标之间的关联性
CPU性能优化的几个思路
性能优化方法论
确定三个问题:
- 判断所做的性能优化是否有效?优化后,能提升多少性能,有多少收益?
- 如果有多个性能问题同时存在,应该先优化哪一个?
- 当有多种优化的方法,应该选择哪一种?
怎么评估性能优化的效果
三步走的原则:
- 确定性能的量化指标
- 测试优化前的性能指标
- 测试优化后的性能指标
第一步,性能的量化指标包括CPU使用率、应用的吞吐量、响应时间等等,不要局限在单一维度的指标上。例如,以Web应用为例:
- 应用程序的维度,使用吞吐量和请求延时来评估
- 系统资源的维度,使用CPU使用率来评估
好的应用程序是性能优化的最终结果和目的,要使用应用程序的指标,来评估性能优化的整体效果;而系统资源的使用情况是影响应用程序的根源,需要用资源的指标,来分析应用性能的瓶颈来源
第二三步,对比第一步确定的量化指标在优化前后的差距,拿数据说话。例如,使用ab工具测试Web应用的并发请求数和响应延时,同时使用vmstat,pidstat等工具,观察系统和进程的CPU使用率,同时获得了应用和系统两个维度的性能指标
进行性能测试需要注意的是:
- 要避免性能测试工具干扰应用程序的性能
- 避免外部环境的变化影响性能指标的评估。在优化前、后的应用程序,都运行在相同配置的机器上,并且它们的外部依赖也要完全一致
多个性能问题同时存在,怎么选择?
遵循二八原则,80%的性能问题都是由于20%的代码导致的,并不是所有的性能问题都值得优化
分析的步骤:
- 挨个分析出所有的性能瓶颈,排除掉有因果关系的性能问题
- 在剩下的几个性能问题中,选择能明显提升应用性能的问题进行修复,有两种方法:
- 如果系统资源出现瓶颈,首先优化系统资源使用的问题
- 针对不同类型的指标,,首先优化导致性能指标变化幅度最大的那些瓶颈问题
有多种优化方法时,如何选择?
性能优化并非没有成本。
一个很典型的例子网络中的 DPDK(Data Plane Development Kit)。DPDK 是一种优化网络处理速度的方法,它通过绕开内核网络协议栈的方法,提升网络的处理能力。不过它有一个很典型的要求,就是要独占一个 CPU 以及一定数量的内存大页,并且总是以 100% 的 CPU 使用率运行。所以,如果你的 CPU 核数很少,就有点得不偿失了。
因此,在考虑性能优化方法时,要结合实际情况,考虑多方面的因素,进行权衡在做选择
CPU优化
应用程序优化
常见的几种优化方法:
- 编译器优化:很多编译器都会提供优化选项,适当开启它们,在编译阶段你就可以获得编译器的帮助,来提升性能。比如, gcc 就提供了优化选项 -O2,开启后会自动对应用程序的代码进行优化。
- 算法优化:使用复杂度更低的算法,显著加快处理速度
- 异步处理:使用异步处理,可以避免程序因为等待某个资源而一直阻塞,从而提升程序的并发处理能力。比如,把轮询替换为事件通知,就可以避免轮询耗费 CPU 的问题。
- 多线程代替多进程:前面讲过,相对于进程的上下文切换,线程的上下文切换并不切换进程地址空间,因此可以降低上下文切换的成本。
- 善用缓存:经常访问的数据或者计算过程中的步骤,可以放到内存中缓存起来,这样在下次用时就能直接从内存中获取,加快程序的处理速度。
系统优化
常见的系统优化方法:
- CPU 绑定:把进程绑定到一个或者多个 CPU 上,可以提高 CPU 缓存的命中率,减少跨 CPU 调度带来的上下文切换问题
- CPU 独占:跟 CPU 绑定类似,进一步将 CPU 分组,并通过 CPU 亲和性机制为其分配进程。这样,这些 CPU 就由指定的进程独占,换句话说,不允许其他进程再来使用这些 CPU
- 优先级调整:使用 nice 调整进程的优先级,正值调低优先级,负值调高优先级。可以适当降低非核心应用的优先级,增高核心应用的优先级,可以确保核心应用得到优先处理
- 为进程设置资源限制:使用 Linux cgroups 来设置进程的 CPU 使用上限,可以防止由于某个应用自身的问题,而耗尽系统资源。
- NUMA(Non-Uniform Memory Access)优化:支持 NUMA 的处理器会将内存划分为多个 node,每个 node 关联到系统的一个处理器。NUMA 优化,其实就是让 CPU 尽可能只访问本地内存。
- 中断负载均衡:无论是软中断还是硬中断,它们的中断处理程序都可能会耗费大量的 CPU。开启 irqbalance 服务或者配置 smp_affinity,就可以把中断处理过程自动负载均衡到多个 CPU 上。
避免过早优化
性能优化最好是逐步完善,动态进行,不追求一步到位,而要首先保证能满足当前的性能要求。当发现性能不满足要求或者出现性能瓶颈时,再根据性能评估的结果,选择最重要的性能问题进行优化
总结
要忍住“把 CPU 性能优化到极致”的冲动,因为 CPU 并不是唯一的性能因素,还会有其他的性能问题,比如内存、网络、I/O 甚至是架构设计的问题。
如果不做全方位的分析和测试,只是单纯地把某个指标提升到极致,并不一定能带来整体的收益。