Linux调试原理及方法2——内存占用调优
Linux 调试系列文章
[[Linux CPU 占用调优]]
[[Linux Memory占用调优(Processing)]]
调试工具总览
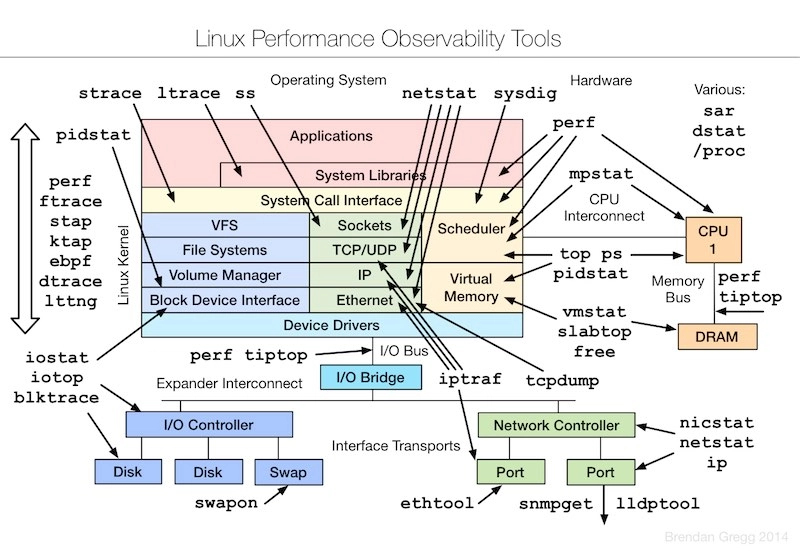
Brendan D. Gregg 维护了一份Linux性能调优工具的蓝图Linux Performance Tools,针对Linux系统的各个组件都有相应的分析工具,一目了然。
基本原理
linux内核内存管理
-
【批发】linux内核基于伙伴算法管理物理内存页
-
【零售】linux内核基于slab管理内存
-
linux内核所用物理内存大小统计
linux进程内存管理
malloc() 是 C 标准库提供的内存分配函数,对应到系统调用上,有两种实现方式,即 brk() 和 mmap()
对小块内存(小于 128K),C 标准库使用 brk() 来分配,也就是通过移动堆顶的位置来分配内存。这些内存释放后并不会立刻归还系统,而是被缓存起来,这样就可以重复使用。
对大块内存(大于 128K),则直接使用内存映射 mmap() 来分配,也就是在文件映射段找一块空闲内存分配出去
各自的优缺点:
-
brk() 方式的缓存,可以减少缺页异常的发生,提高内存访问效率;不过,由于这些内存没有归还系统,在内存工作繁忙时,频繁的内存分配和释放会造成内存碎片
-
mmap() 方式分配的内存,会在释放时直接归还系统,所以每次 mmap 都会发生缺页异常。在内存工作繁忙时,频繁的内存分配会导致大量的缺页异常,使内核的管理负担增大
整体来说,Linux 使用伙伴系统来管理内存分配。前面我们提到过,这些内存在 MMU 中以页为单位进行管理,伙伴系统也一样,以页为单位来管理内存,并且会通过相邻页的合并,减少内存碎片化(比如 brk 方式造成的内存碎片)
虚拟内存
- 进程独享虚拟地址空间(32位) 0~3G
- 进程内分段管理内存空间
代码段
数据段
heap
malloc()
stack
文件映射,匿名映射 mmap()
进程内存按照用途分类

物理内存
进程所用物理内存大小统计
- PSS
一个进程所使用的内存可通过PSS和RSS来衡量。 计算进程的Pss: $ cat /proc/1/smaps | grep Pss | awk ‘{total+=$2}; END {print total}’
把一个共享库占用的内存,分摊到使用了这个共享库的各个进程头上
- RSS(不合理)
把共享库占用的内存直接加到每个进程头上
- USS
进程独自占用的物理内存(不包含共享库占用的内存)
内存回收
在用户空间,malloc 通过 brk() 分配的内存,在释放时并不立即归还系统,而是缓存起来重复利用。在内核空间,Linux 通过 slab 分配器来管理小内存,可以把 slab 看成构建在伙伴系统上的一个缓存,主要作用就是分配并释放内核中的小对象
系统也不会任由某个进程用完所有内存。在发现内存紧张时,系统就会通过一系列机制来回收内存:
-
回收缓存,比如使用 LRU(Least Recently Used)算法,回收最近使用最少的内存页面
-
回收不常访问的内存,把不常用的内存通过交换分区直接写到磁盘中(会用到交换分区)
-
杀死进程,内存紧张时系统还会通过 OOM(Out of Memory),直接杀掉占用大量内存的进程
OOM是内核的一种保护机制。它监控进程的内存使用情况,并且使用 oom_score 为每个进程的内存使用情况进行评分:
-
进程消耗的内存越大,oom_score 就越大
-
进程运行占用的 CPU 越多,oom_score 就越小
可以手动设置进程的oom_adj来调整oom_score。oom_adj的范围是[-17, 15],数值越大,进程越容易被OOM杀死;反之,越不容易被OOM杀死
回收时机
- 内存紧缺回收(alloc_pages的时候)
- 周期性内存回收:linux内存回收总结:从swapd触发到回收3部曲
- 手动回收
1 | echo 1 > /proc/sys/vm/drop_caches # "clean" page cache |
回收方式
- 页回写 直接释放物理页面
- 页交换 回写到swap分区,然后释放物理页面
- OOM Killer (较为暴力,应尽量避免)
性能指标
系统内存使用量
buffer, cache, used
相关工具
1 | /proc/meminfo |
系统内存余量
free, available
available等于“空闲内存减去所有zones的lowmem reserve和high watermark,再加上page cache和slab中可以回收的部分“
进程虚拟内存
1 |
|
/proc/{id}/maps
pmap -p 1
进程内存使用量
相关工具
ps -aux
top
RES:常驻内存大小
RES=RSan+RSfd+RSsh
RSan:常驻匿名内存大小
RSfd:常驻文件映射内存大小
RSsh:常驻被锁定内存大小
SHR:共享内存大小
/proc/{pid}/status
smem -k -s rss| more
缓存与缓冲区命中率
缓存命中率,是指直接通过缓存获取数据的请求次数,占所有数据请求次数的百分比。
相关工具
cachestat/cachestat-bpfcc(系统整体)
HITS ,表示page cache命中的次数; MISSES ,表示page caceh未命中的次数; DIRTIES, Number of dirty pages added to the page cache; BUFFERS_MB,表示 Buffers 的大小,以 MB 为单位; CACHED_MB,表示 Cache 的大小,以 MB 为单位; HITRATIO,表示 page cache 命中率;
cachetop/cachetop-bpfcc(进程)
pcstat (进程&文件)
swap分区使用量
swap分区的作用是在系统物理内存不足时,将一部分物理内存中的数据交换到swap分区(磁盘上),从而把这部分物理内存释放出来给需要的程序来使用。 一、哪部分内存会被交换到swap分区? 1、匿名页(AnonPages); 2、Shmem(基于tmpfs实现)虽然未统计在AnonPages里,但它们背后没有硬盘文件,所以也是需要交换区的。 二、从进程角度看,以下的函数或者机制分配的内存在物理内存不足时会被交换到swap分区,包括: - stack - malloc() - brk()/sbrk() - mmap(PRIVATE, ANON) - POSIX shm* - mmap(SHARED, ANON) - tmpfs
相关工具
free(系统整体)
sar -S 1(系统整体)
smem -k(进程)
计算所有进程的swap总的大小: $ smem | awk ‘{if(NR>1) total+=$(NF-3)}; END{printf total}’
内存泄露情况
相关工具
memleak -a -p {pid}
1 | leak.c |
缺页异常(主、次)
缺页异常:cpu拿到虚拟地址,让MMU进行地址转换的时候,MMU找不到虚拟地址的页表映射关系。 主缺页:需要从磁盘加载 memory page; 次缺页:不需要从磁盘加载 memory page;
相关工具
进程自启动以来发生的缺页事件的总和:
ps -eo min_flt,maj_flt,cmd | more
进程每秒缺页错误次数:
pidstat -r
工具汇总
free命令
1 | # 注意不同版本的free输出可能会有所不同 |
- 第一列,total 是总内存大小;
- 第二列,used 是已使用内存的大小,包含了共享内存;
- 第三列,free 是未使用内存的大小;
- 第四列,shared 是共享内存的大小;
- 第五列,buff/cache 是缓存和缓冲区的大小;
- 最后一列,available 是新进程可用内存的大小
注意:available 不仅包含未使用内存,还包括了可回收的缓存,所以一般会比未使用内存更大。不过,并不是所有缓存都可以回收,因为有些缓存可能正在使用中
top命令
可以查看每个进程的内存使用情况
1 | # 按下M切换到内存排序 |
主要的几个信息:
- VIRT 是进程虚拟内存的大小,只要是进程申请过的内存,即便还没有真正分配物理内存,也会计算在内
- RES 是常驻内存的大小,也就是进程实际使用的物理内存大小,但不包括 Swap 和共享内存
- SHR 是共享内存的大小,比如与其他进程共同使用的共享内存、加载的动态链接库以及程序的代码段等
- %MEM 是进程使用物理内存占系统总内存的百分比
注意:
- 虚拟内存通常并不会全部分配物理内存。从上面的输出,你可以发现每个进程的虚拟内存都比常驻内存大得多
- 共享内存 SHR 并不一定是共享的,比方说,程序的代码段、非共享的动态链接库,也都算在 SHR 里。SHR 也包括了进程间真正共享的内存。所以在计算多个进程的内存使用时,不要把所有进程的 SHR 直接相加得出结果
sar
用法: sar -r -S 1
-r: 表示显示内存使用情况
kbcommit,表示当前系统负载需要的内存。它实际上是为了保证系统内存不溢出(不超出),对需要内存的估计值。 %commit,就是这个值相对总内存的百分比,因为commit统计的是RAM+swap,所以%commit可能会大于100%
-S: 表示显示Swap使用情况
kbswpcad:其实就是swap文件的file cache。 kbswpcad = SwapCached(来自/proc/meminfo)
vmstat
用法
1 | -f: 显示系统启动到今创建的所有的进程数 |
cachestat/cachestat-bpfcc
安装方法: $ sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 4052245BD4284CDD $ echo “deb https://repo.iovisor.org/apt/xenial xenial main” | sudo tee /etc/apt/sources.list.d/iovisor.list $ sudo apt-get update $ sudo apt-get install -y bcc-tools libbcc-examples linux-headers-$(uname -r) $ export PATH=$PATH:/usr/share/bcc/tools
用法
HITS ,表示page cache命中的次数; MISSES ,表示page caceh未命中的次数; DIRTIES, Number of dirty pages added to the page cache; BUFFERS_MB,表示 Buffers 的大小,以 MB 为单位; CACHED_MB,表示 Cache 的大小,以 MB 为单位; HITRATIO,表示 page cache 命中率;
提供了整个系统的 page cache 的读写命中情况
cachetop/cachetop-bpfcc
用法
提供了每个进程的 page cache 的读写命中情况
pcstat
安装方法: $ export GOPATH=~/go $ go get github.com/tobert/pcstat $ cp -rfa $GOPATH/bin/pcstat /bin
用法
查看文件的缓存大小以及缓存比例:
$ pcstat /tftpboot/hello
查看进程打开的所有文件的缓存大小以及缓存比例:
$ pcstat -pid {pid}
hcache
go version > 1.12 【安装】 git clone https://github.com/silenceshell/hcache.git cd hcache make build sudo cp hcache /usr/local/bin/
用法
输出系统中前10大使用缓存最多的文件:
hcache --top 10
只显示基本名字:
hcache --top 10 -basename
memleak
memleak跟踪内存申请和释放请求。 【实现原理】 在跟踪某个进程时,memleak会追踪libc中的分配函数,具体来说包括:malloc、calloc、realloc、valloc、memalign、pvalloc、aligned d_alloc和free; 当跟踪所有进程时,memleak追踪包括kmalloc/kfree、kmem_cache_alloc/kmem_cache_free,以及get_free_pages/free_pages所分配的页面。
用法
-a: 表示显示每个内存分配请求的大小以及地址
-p {pid}:指定要检测的进程
-c {command}:运行指定的命令并只跟踪其分配,这会跟踪libc分配器。
-z {MIN_SIZE}:只捕获大于等于MIN_SIZE字节的内存泄露
-Z {MAX_SIZE}:只捕获小于等于MAX_SIZE字节的内存泄露
INTERVAL:每隔INTERVAL秒打印未释放的申请及其调用堆栈的摘要。缺省值为5秒。
每隔1秒打印一次进程31826的内存泄露统计:
memleak -a -p 31826 1
限制
当追踪的进程快速申请和释放内存时,memleak可能会带来很大的开销
此工具仅适用于Linux 4.6+
smem
用法
统计物理内存用量,支持的维度:process, user, mapping, systemwide
-k:显示单位后缀
-p:用百分比显示
-u:显示用户占用内存信息swap/rss/uss/pss大小
-w:显示系统内存用量,包括内核空间和用户空间
-m:统计mapping所用的物理内存
$ smem -m -k Map PIDs AVGPSS PSS /lib/x86_64-linux-gnu/libc-2.27.so 173 29.0K 5.1M 第一列(Map): 表示被共享的文件名字; 第二列(PIDs): 表示上述文件被几个进程共享; 第三列(AVGPSS): 各个进程平均分摊的内存,AVGPSS=PSS/PIDs 第四列(PSS): 文件加载后,占用的物理内存;
-s {swap/pss/uss/rss}:按照进程对swap/rss/pss/uss的使用量排序
调优实践
实践一:linux c语言开发遇到的最常见的内存问题,该如何定位解决?
分析过程
查看系统总体内存用量,确定大致问题:
vmstat -S K 1
对使用物理内存最多的20个进程进行监控(间隔1s),确定进程是否存在内存异常:
watch -n 1 -d “smem -s rss |tail -n 20”
如果进程使用内存持续增加,进行内存泄露监控:
memleak -a -p {pid} 1
对其他内存使用量较高的进程代码进行review,主要关注如下部分:
- malloc
- brk()/sbrk()
- mmap()
- shmem等
进行代码层面的性能优化
环境搭建
1 | main.c |
实践二:spark处理200w笔数据,有时候需要几秒,有时候需要几十秒,原因何在?
分析过程
检查程序执行过程中有没有涉及到文件的操作?
lsof -p 28161| grep test.csv
查看文件的缓存命中情况
pcstat /app/tools/test-tool/data/test.csv
记录测试结果
清除文件缓存
echo 1 > /proc/sys/vm/drop_caches
查看缓存命中情况
记录测试结果
结论:由于文件缓存的作用,性能提升了10倍左右!
1 | spark-sql> |
调优方法
应用层面
尽量使用缓存或者缓冲区来缓存数据
fluent-bit; flume; spark等
考虑使用tmpfs替代磁盘目录
mount -t tmpfs -o size=1G tmpfs /tftpboot/spark
系统层面
减少swap使用,比如减少swappiness大小
限制进程内存资源
使用HugePage(大页内存,4k->2M, 1G等),提高TLB的命中率
通过 /proc/pid/oom_adj ,调整核心应用的 oom_score
范围 【-17,+15】,值越大越被容易杀死