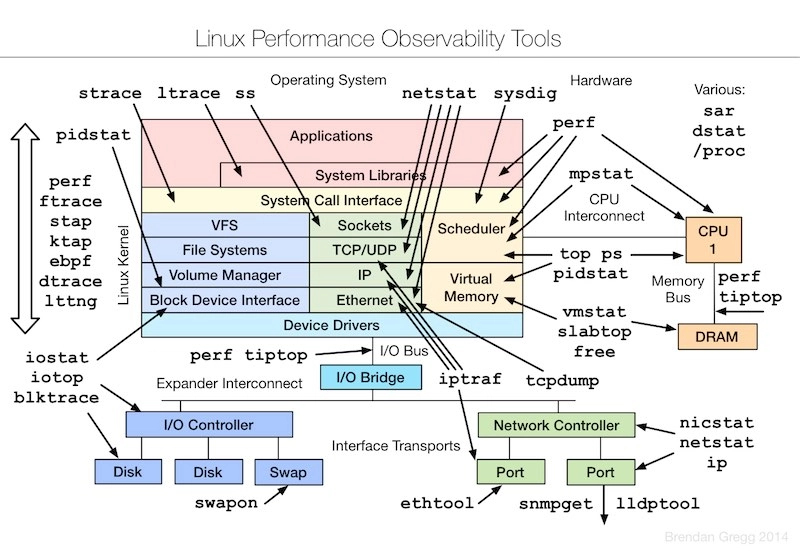
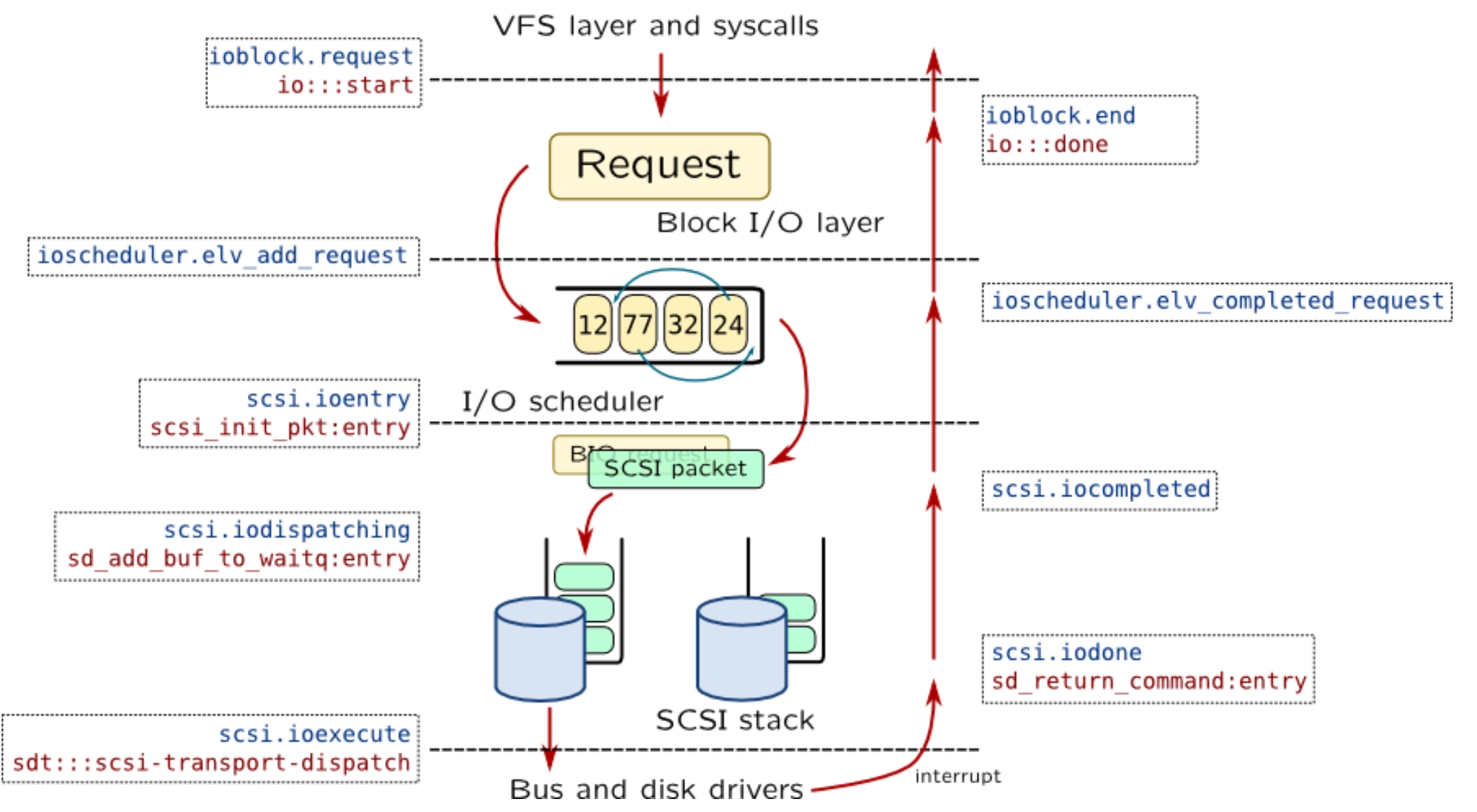
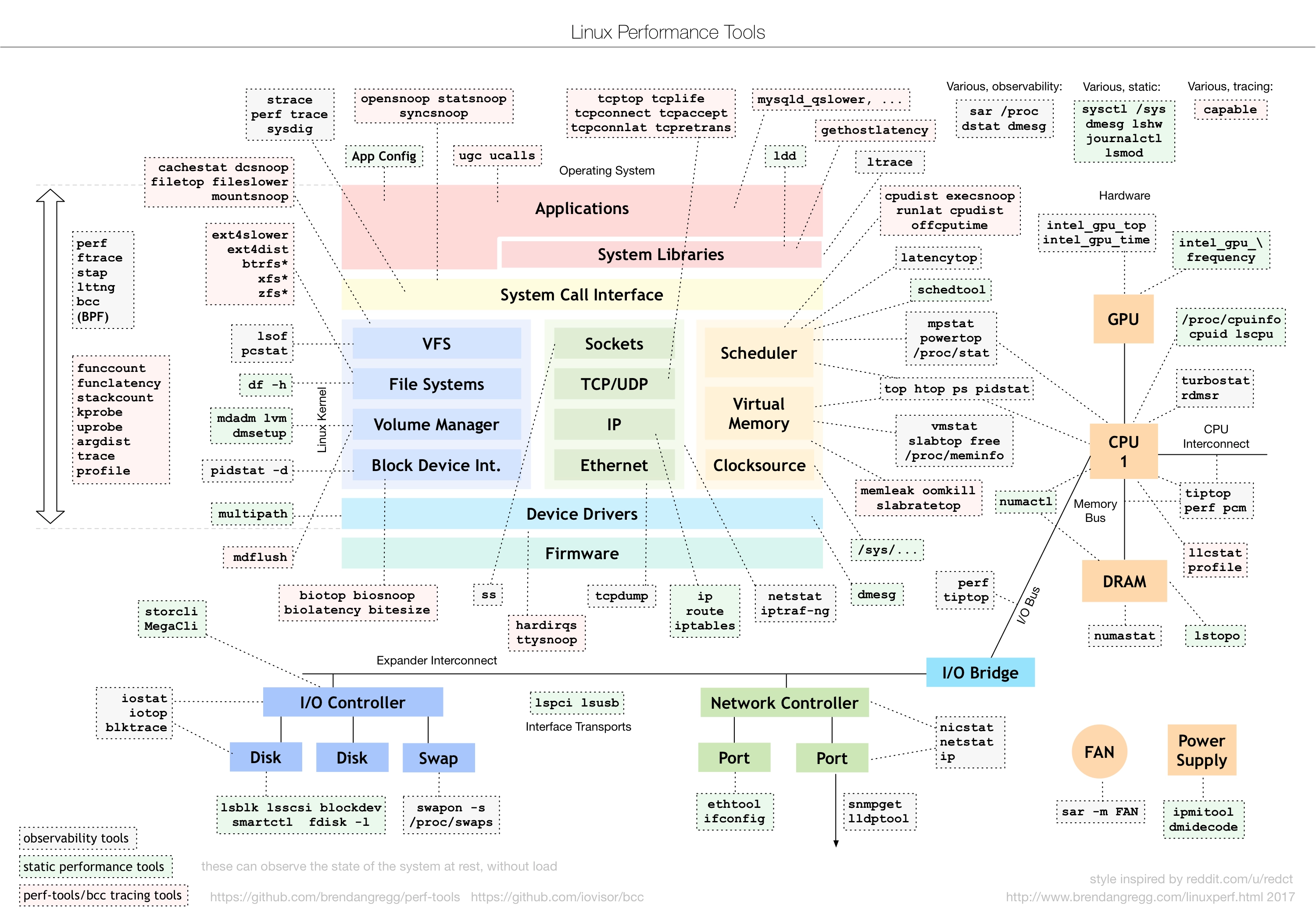
Linux——网络调优
Linux 网络调优
基本原理
TCP/IP五层模型
- 应用层
负责应用程序沟通,常见协议:http/ftp/tftp/snmp/smtp/telnet等,可自定义
- 传输层
提供端到端的通信服务,常见协议:tcp和udp协议
- 网络层
负责数据的分片、寻址和路由,常见协议:ip协议
- 数据链路层
负责硬件设备之间的数据帧的传送和识别,例如帧同步、冲突检测等,常见协议:ethernet协议
- 物理层
透明的传输比特流,常见硬件厂商:
- broadcom(博通)
- realtek(瑞昱)
- intel
实践一、linux c实现聊天功能及wireshark抓包分析
案例代码在这里 ->
https://github.com/simple-tec/linux-driver/tree/main/app/tcp
linux网络设备驱动
(以dm9000芯片为例)
硬件datasheet在这里 ->
http://www.davicom.com.tw/pddocs/DM9000A-DS-F01-030311.pdf
最大传输单元mtu
mtu范围:【68, 1500】
ip报头最小:20 Bytes
tcp头部最小:20 Bytes
最大mss = 1500-20-20=1460
最大报文段长度(MSS)是TCP协议的一个选项,用于在TCP连接建立时,收发双方协商通信时每一个报文段所能承载的最大数据长度(不包括文段头)。 MSS = MTU - TCP头部大小 - IP头部大小 其中,TCP 头部和 IP 头部的大小是固定的,分别为 20 字节和 20 字节。
mtu限制了数据链接层上可以传输的数据包的大小,也因此限制了上层(IP层)的数据包大小
mtu和IP分片的关系
当要求发送的IP数据包比数据链路层的MTU大时,必把该数据包分割成多个IP数据包才能发送。
linux网卡驱动发送和接收
参考代码(linux 4.9.229):drivers/net/ethernet/davicom/dm9000.c
网卡驱动整体框架
- 数据帧发送
1、dm9000_start_xmit()
2、 dm9000_interrupt()
3、dm9000_tx_done
- 数据帧接收
1、 dm9000_interrupt()
2、dm9000_rx()
3、netif_rx()
- 软中断NET_TX, NET_RX处理
参考代码(linux 4.9.229):net/core/dev.c
网络底半部发送:net_tx_action()
网络底半部接收:net_rx_action()
性能指标
最大传输单元mtu
相关工具
查看:
ifconfig eth0 | grep mtu
修改(临时):
ifconfig eth0 mtu 1450
实践:IP数据包(包含IP头)超过MTU大小,会发生什么情形?
操作步骤
【假设】eth0接口的mtu为1500! 命令1: ping -I eth0 -s 1472 -M do 192.168.0.101 命令2: ping -I eth0 -s 1473 -M do 192.168.0.101
带宽
链路的最大传输速度,单位b/s(比特/s),属于基础设施。
相关工具
ethtool eth0 | grep Speed
PPS
Packet Per Second,表示以网络包为单位的传输速率
相关工具
sar -n DEV
吞吐量
单位时间内传输的数据量,单位b/s或者B/s
相关工具
sar -n DEV
rxpck/s 和 txpck/s 分别是接收和发送的 PPS; rxkB/s 和 txkB/s 分别是接收和发送的吞吐量; rxcmp/s 和 txcmp/s 分别是接收和发送的压缩数据包数; %ifutil 是网络接口的使用率,即半双工模式下为 (rxkB/s+txkB/s)/Bandwidth,而全双工模式下为 max(rxkB/s, txkB/s)/Bandwidth;
往返延时(RTT)
RTT(Round-Trip Time): 往返时延。在计算机网络中它是一个重要的性能指标,表示从发送端发送数据开始,到发送端收到来自接收端的确认(接收端收到数据后便立即发送确认),总共经历的时延。
相关工具
【ICMP】ping -c4 8.8.8.8
ping命令的输出中的最后一行: rtt min/avg/max/mdev = 58.325/71.634/94.710/14.502 ms mdev全称Mean Deviation,译为平均方差 mdev越大,表示网络越不稳定。
【TCP】hping3 -c 3 -S -p 80 httpbin.org
TCP相关性能工具
tcp半连接队列的大小
相关工具
max(64, net.ipv4.tcp_max_syn_backlog)
tcp全连接队列的大小
相关工具
min(backlog, net.core.somaxconn)
tcp/udp吞吐量
相关工具
【tcp】
server端:iperf -s -p 10000
client端:iperf -c 192.168.0.100 -p 10000
【udp】
server端:iperf -s -p 10000
client端:iperf -u -c 192.168.0.100 -p 10000
tcp缓冲区大小
相关工具或配置
tcp发送缓冲区大小:
查看:
cat /proc/sys/net/ipv4/tcp_wmem
该文件包含3个整数值,分别是:min,default,max
更改:
sysctl -w net.ipv4.tcp_wmem=“XXXX XXXX XXXX”
tcp接收缓冲区大小:
查看:
cat /proc/sys/net/ipv4/tcp_rmem
该文件包含3个整数值,分别是:min,default,max
更改:
sysctl -w net.ipv4.tcp_rmem=“XXXX XXXX XXXX”
socket连接数
相关工具
查看tcp状态为SYN_REC的sockets:
netstat -n -p -t | grep SYN_REC
查看tcp状态为SYN_REC的sockets:
ss -n -p -t | grep SYN_REC
UDP相关性能工具
udp缓冲区大小
相关工具或配置
udp缓冲区大小:
查看:
cat /proc/sys/net/ipv4/udp_mem
该文件包含3个整数值,分别是:min,default,max
套接字缓冲区大小
单个套接字缓冲区大小
相关工具或配置
setsockopt(,SO_SNDBUF,)配置
在调用connect或listen之前通过setsockopt设置。
setsockopt(,SO_RCVBUF,)配置
在调用connect或listen之前通过setsockopt设置。
内核全局的套接字缓冲区大小
相关工具或配置
套接字接收缓冲区大小:
查看:
cat /proc/sys/net/core/rmem_max
修改:
sysctl -w net.core.rmem_max=212993
套接字发送缓冲区大小:
查看:
cat /proc/sys/net/core/wmem_max
修改:
sysctl -w net.core.wmem_max=212993
工具汇总
wireshark
用法
过滤器
捕获过滤器:用于决定捕获什么数据
显示过滤器:在捕获的结果中进行详细查找
详细语法:

比较运算:
逻辑运算:
例子
frame.cap_len > 100
【备注】cap_len长度包括【以太网头+ip头+tcp头+应用数据】的总长度
ip.len >= 100
【备注】ip.len是ip层以上的(包含ip头)数据的总长度
tcp.len >= 60
【备注】tcp.len即tcp segment len,指的是tcp所承载的应用数据的长度(不包含tcp头部)
udp.length > 100
【备注】udp.length是udp报头和udp载荷数据的总大小
对多个条件进行过滤:
ip.addr==172.16.10.2 and tcp.flag.fin
按字节位置的内容进行过滤(十六机制):
tcp[0:2]==ac3a(匹配源端口号44090)
【备注】tcp[n,m] :n是起始位置偏移,m是从指定位置的区域长度
按比特位置的内容进行过滤:
tcp[13]&2
【备注】用“&2”符号指出要取这个字节中第2位即SYN位置的值
tcp.segment_data contains 49:27:6d:20:64:61:74:61
【备注】49:27:6d:20:64:61:74:61是16进制的内容序列
Flow Graph
1, 在选择一个包后,单击右键并选择 “Follow” -> “TCP Stream”; 2,关闭弹出来的对话框,回到 Wireshark 主窗口。这时候,你会发现 Wireshark 已经自动帮你设置了一个过滤表达式,例如:tcp.stream eq 24。 从这里,你可以看到这个 TCP 连接从三次握手开始的每个请求和响应情况。 3,为了更加直观,你可以继续点击菜单栏里的 Statics -> Flow Graph,选中 “Limit to display filter” 并设置 Flow type 为 “TCP Flows”。就可以看到更直观的通信细节。
tcpdump
用法
-i eth0:指定网络接口
-nn:不解析ip地址和端口号的名称
-c {count}:指定要抓取的数据包的个数
-w {file}:抓包并保存到文件,比如:file.pcap
[expression] tcpdump的过滤表达式和wireshark是类似的
tcpdump的过滤表达式
输出格式:时间戳 协议 源IP地址:源端口 > 目的IP地址:目的端口 网络包详细信息
例子:tcpdump -i eth0 icmp and host 192.168.0.102 -nn
netstat
用法
-a: 显示所有的socket连接(包括listening和non-listening连接)
-l: 只显示listening状态的socket连接
-n: 表示显示数字地址和端口(而不是名字)
-p: 表示显示进程信息
-t: 只显示tcp连接(若不指定-l,则默认仅显示non-listening连接)
-u: 只显示udp连接(若不指定-l,则默认仅显示non-listening连接)
-x: 只显示unix连接
-i: 显示所有网络接口的状态
-s:汇总了 ip、icmp、udp、tcp 等各种协议的收发统计信息
ip
Forwarding: 1 //开启转发 8641328 total packets received //总收包数 73 with invalid addresses // 有着错误地址的封包数 0 forwarded //转发包数 0 incoming packets discarded //接收丢包数 8598954 incoming packets delivered //接收的数据包数 5161967 requests sent out //发出的数据包数 160 dropped because of missing route //找不到路由而导致的丢包数 1 fragments dropped after timeout //超时导致的丢包数 274 reassemblies required //需要重组的封包数 117 packets reassembled ok//重组成功的封包数 1 packet reassemblies failed //重组失败的封包数
-e:显示额外的信息,比如socket path等
-r:显示内核的路由表,等同于route -e
Recv-Q 和 Send-Q的解释
注意,在不同套接字状态下,它们的含义不同: 1、当套接字处于Established状态(Established)时,Recv-Q 表示OS持有的、尚未交付给应用程序的数据的字节数;而 Send-Q 表示已经发送给对端应用,但对端应用尚未ack的字节数。 2、当套接字处于监听状态(Listening)时,Recv-Q 表示当前全连接队列的长度。而 Send-Q 表示全连接队列的最大长度,其值为min(backlog, somaxconn)。 注意,Listening状态时,Recv-Q的最大值为Send-Q+1,即:min(backlog, somaxconn)+1。 之所以加1,是因为OS内核在判断队列是否已满时,用的是>(应该用>=),这导致当已创建成功的连接数量正好等于min(backlog, somaxconn)时,还会再多创建一个tcp连接,最终结果就是:min(backlog, somaxconn)+1。
场景
1、列出所有的tcp端口(包含listen和非listen状态):
$ netstat -ta
列出处于Listen状态的tcp端口:
$ netstat -tl
注意:netstat -t会列出处于no-listen状态的tcp连接
2、显示各个协议的统计信息:
$ netstat -s
3、显示tcp的统计信息
$ netstat -st
4、初步检测你的系统有没有受到DDOS攻击:
$ netstat -n -p|grep SYN_REC | wc -l
ss
用法
-a: 显示所有的sockets(包括LISTEN和非LISTEN)
-l: 只显示LISTEN状态的sockets
-n:不解析服务名字,显示数字和端口
-p:显示进程信息
-t:只显示tcp连接
-u:只显示udp连接
-x:只显示unix连接
-s:连接信息汇总
iperf
用法
-f [kmKM] :分别表示以Kbits, Mbits, KBytes, MBytes显示报告
-s:以server模式启动
-c:以client模式启动
-p:指定端口号
-u:使用udp协议
-t {sec}:表示测试多久,一般指定在client端(因为client为封包发送方)
-m:在结果中打印tcp mss的值
-N:禁止Nagle算法
场景
测试tcp的吞吐量:
server端:iperf -s -p 10000
client端:iperf -c 192.168.0.100 -p 10000
测试udp的吞吐量:
server端:iperf -s -p 10000 -u
client端:iperf -c 192.168.0.100 -p 10000 -u
ab
用法
-c: 并发数
-n: 总请求数
-s: 设置每个请求的超时时间
-r: 套接字接收错误时仍然继续执行
注意
测试高并发,需要提前修改进程能打开的最大文件描述符的大小:
$ ulimit -n 10240
场景
测试某个服务的性能:
$ ab -c 100 -n 10000 http://httpbin.org/ip
Failed requests: //失败的请求数; Non-2xx responses://非2xx回应的请求数; Requests per second://每秒完成的请求数; Time per request【1】:每个请求的平均处理时间; Time per request【2】:引入并发因素后,每个请求的平均处理时间; Transfer rate: //每秒数据传输量,表示网络吞吐; 备注: 某些情况下Time per request【2】乘以concurrency,约等于Time per request【1】,希望这样有助于你理解这两者的区别。
hping3
用法
模式选择,默认tcp
–rawip:RAWIP模式
–icmp:ICMP模式
–udp:UDP模式
–scan:SCAN模式,指定扫描对应的端口
–listen:监听模式
-S:表示设置TCP协议的SYN(同步序列号)
-p {port}: 设置端口号
-c {count}:发送的总封包数
-i {interval}:u100表示每隔100微秒发送一个网络帧
-i 1:表示每隔1秒发送一个网络帧; -i u100:表示每隔100微妙发送一个网络帧;
-a {hostname}:源地址欺骗
–rand-source:随机化源IP
–flood:尽量快的发包,无需再指定-i
场景
1、端口扫描
扫描一个端口:
$ hping3 192.168.0.1 --scan 80 -S
扫描多个端口:
$ hping3 192.168.0.1 --scan 80,8080 -S
2、模拟DDOS攻击
SYN ddos攻击:
$ hping3 -S -p 80 -i u10 192.168.0.1
flood+随机源地址SYN攻击:
$ hping3 -S -p 80 192.168.0.1 --flood --rand-source
3、伪造源IP地址
伪装源地址为10.0.0.1给192.168.0.1的80端口发送syn包:
$ hping3 -S -p 80 -a 10.0.0.1 -S 192.168.0.1
ping
用法
-n:不会进行名称解析
-s {packetsize}:指定要发送的封包大小。
【注意】{packetsize}+8+20应该小于等于mtu,否则会执行分片策略
-M {pmtudisc_opt}:选择Path MTU发现策略,可选值如下:
- do:禁止分片
- want:package太大时执行分片
- dont:不设置DF flag
例子:
ping 192.168.0.101 -c 1
nethogs
用法
排序显示每个进程所使用的网络带宽,例如:
nethogs -d 2 -s
-d {seconds}:指定刷新频率
-s:按照网络发送量排序
交互参数:
m:切换byte, kb, mb等
r: 按照接收排序
s:按照发送量排序
iftop
用法
界面参数说明: =>代表发送数据 <=代表接收数据 TX:发送流量(过去 2s 10s 40s ) RX:接收流量(过去 2s 10s 40s ) TOTAL:总流量 Cumm:运行iftop到目前时间的字节总量 peak:过去40s的流量峰值 rates:分别表示过去 2s 10s 40s 的平均流量 备注:流量的单位是Bytes/s,也就是传输速度。
-i ${dev}:设定监测的网卡
-B:以bytes为单位显示流量(默认是bits)
-n:不使用host信息、而是使用ip地址和端口的方式来显示
常用组合:
iftop -i eth0 -B -n
调优实践
实践一、ping不通服务器,该从哪些方面去调试?
分析过程
【物理层】查看网线接口灯的状态是否正常。
绿灯是链路指示灯,黄灯是信号指示灯。 1、黄灯闪动,绿灯长亮 表示链路正常,正在通信中; 2、黄灯不亮,绿灯长亮 表示链接正常,不过目前没有数据通信; 3、黄灯不亮,绿灯闪动 表示链路不稳定,存在比如线头接触不良等问题
【数据链路层】ifconfig查看相应的网络接口是否存在RX errors或者TX errors
$ watch -d ifconfig eth0
【arp层】查看本地的arp缓存中关于目标ip的mac地址是否正确?
$ arp -e
【网络层】执行route查看针对目标IP的出口设备是否正常?有时docker bridge就创建它自己的172打头的路由规则,导致路由出错
【本机的软件防火墙】通过iptables -L查看是否有针对目标服务器地址的可疑规则
【第三方防火墙】和服务器机器是否直连,中间有没有通过其他设备,该设备有无防火墙规则设定?
【Tcp层】通过nmap -sS -v 172.21.84.140或则nmap -sT -v 172.21.84.140扫描服务器开关机状态和存活端口号
实践二、对端socket发出了RST报文,导致连接异常关闭,该怎么分析?
分析过程
通过wireshark或tcpdump分析tcp通信过程
RST是发生在3次握手过程中吗?是否在向一个未监听的端口发送
SYN封包?
客户端和服务端程序有任何一方发生了异常退出吗?
是否在已关闭的socket上收到了数据呢?
客户端和服务端程序有任何一方发生了提前close退出吗?
案例代码
在已经关闭的socket上收到了数据,底层协议栈会发RST
1 |
|
client.c
1 |
|
wireshark截图

接收方应用程序未接收完接收缓冲区的数据、就提前close退出,底层协议栈会发RST
Server.c
1 |
|
Client.c
1 |
|

实践三、压测nginx服务时网络延迟居高不下,该如何解决?
环境搭建
1 | 1. nginx打开nagle算法 |
分析过程
[Nagle算法和tcp延迟确认](https://shimo.im/docs/nPixnamNKxQiG7dQ/ 《Nagle算法和tcp延迟确认-public》,可复制链接后用石墨文档 App 打开)
调优方法
数据链路层
网卡驱动优化
NAPI:中断+轮询
为网卡中断配置cpu亲和性(smp_affinity),将这些中断处理程序调度到不同的 CPU 上执行
DPDK
跳过逻辑复杂的linux网络协议栈,直接由用户态进程用轮询的方式,来处理网络请求
传输层
tcp
tcp TIME_WAIT优化
增大处于 TIME_WAIT 状态的连接数量: net.ipv4.tcp_max_tw_buckets
tcp_max_tw_buckets控制kernel中最多存在的TIME_WAIT数量。
减小 net.ipv4.tcp_fin_timeout,让处于FIN状态的tcp连接尽早释放
开启端口复用 net.ipv4.tcp_tw_reuse,这样被 TIME_WAIT 状态占用的端口,能很快被用于新的连接
增加可用端口号或者文件数
增大本地端口的范围 net.ipv4.ip_local_port_range ,这样就可以支持更多连接,提高服务并发能力
linux里,一切皆是文件,socket连接也是,可增加最大文件描述符的数量(ulimit -n 10240)
SYN相关优化
增大 TCP 半连接的最大数量:net.ipv4.tcp_max_syn_backlog
减少 SYN_RECV 状态的连接重传 SYN+ACK 包的次数 :net.ipv4.tcp_synack_retries。
其他优化
tcp nagle算法
启用时可提高小封包场景下的网络利用率,但同时也增加了网络延迟
tcp延迟确认
提高某些场景下的网络利用率
udp
增大UDP的缓冲区大小
跟前面 TCP 部分提到的一样,增大本地端口号的范围
根据 MTU 大小,调整 UDP 数据包的大小,减少或者避免分片的发生
配置套接字缓冲区大小
参考出处:
linux-4.9.229/Documentation/sysctl/net.txt
net.core.optmem_max:每个套接字允许的最大辅助缓冲区大小
net.core.rmem_max:最大接收套接字缓冲区大小(以字节为单位)
net.core.wmem_max:最大发送套接字缓冲区大小(以字节为单位)
应用程序
使用epoll取代select和poll
尽量使用连接池,比如postgres和redis编程都支持连接池方式,可避免每次请求的时候都要建立3次握手
为socket配置较大的套接字的缓冲区SO_SNDBUF和SO_RCVBUF
使用缓存技术,缓存一部分实时性没那么高的数据,减少不必要的网络访问